Data Engineering이라는 분야가 새로 떠오르고 있는데 비교적 새 분야다 보니 너무 알려진 정보가 없었다. 그래서 해당 포지션의 일자리를 알아볼 때 참 고심이 많았다. Data engineering이란 무엇이고, 해당 포지션은 대체 무엇을 하는 포지션인가? 어떤 사람을 찾고자 하는가? 그래서 나 스스로도 공부할 겸 관련하여 좀 정리해 보았다.
본인도 Cloud 관련 분야에 종사한 지 얼마 안 되었고 데이터 엔지니어링과는 다소 거리가 있어서 정리한 내용의 신뢰도에 대해서는 책임질 수가 없다.
Data engineer roadmap repository 2021
로드맵을 저장소로 관리하고 있다. 하나하나씩 확인해보자.
CS Fundamentals
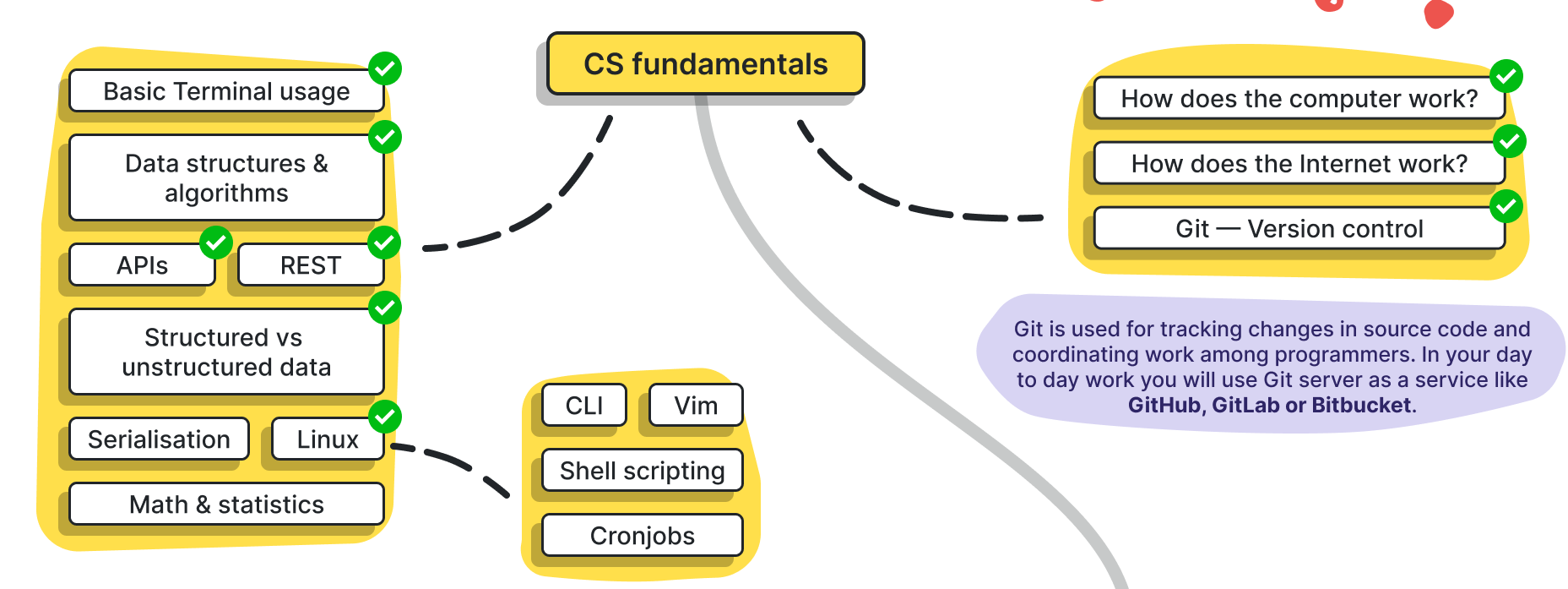
- 자료구조, 인터넷 구조(TCP-IP 및 HTTP 프로토콜?), OS 기초, 리눅스 기초 등...
- 의외로 터미널 사용, Git이 포함되어 있다. 실무진에서는 당연히 알고 있을거란 기대 때문인지 막상 거의 신경 안 쓰는 분위기지만, 프로그래밍 IDE 쪽에 더 가깝지 않나 하는 생각이 ... ㅎㅎ;
Programming language

- 작자는 Python을 선호하는데, Java를 많이 쓴다고 한다. 아무래도 아직 보수적인 비즈니스들이 많은 관계인 것 같다.
- 알아본 바로는 신생 비즈니스에서는 시작 비용이 비교적 저렴한 Golang을 많이 쓰는 것으로 보인다.
- Scala는 아직 쓰는 곳을 못 들었다. Kafka 때문인가? (혹은 그 시절의 여파...)
- Data scientist 분야라면 R 언어 선호도가 꽤 높기 때문에 간략하게라도 알아두는 쪽이 좋을 것 같다.

테스트에 대한 개념
- 유닛 테스트와 통합 테스트 관련 이야기.
- 여기까지만 잘 할수 있어도 솔직히 상위권 개발자에 든다고 생각한다. 현실은 냉혹한 법...
데이터베이스 기초
- SQL과 Normalization(정규화; 무결성 유지), ACID Transaction에 대한 기본적 개념.
- 더 나아가서는 반대개념인 BASE, 그리고 결과적 일관성(Eventually Consistent) 개념까지 짚고 넘어가기
- 데이터의 정합성과 트랜젝션에 대한 기초 개념을 쌓고 가야 한다.
- OLTP / OLAP에 대한 개념도 같이.
- 스케일링 측면에서는 Horizontal(Scale out) / Vertical scaling(Scale up) 짚고 넘어갈 수 있다.
- Dimension 테이블에 관한 개념도 간단하게만 짚고 넘어간다.
관계형 데이터베이스 (RDBMS)
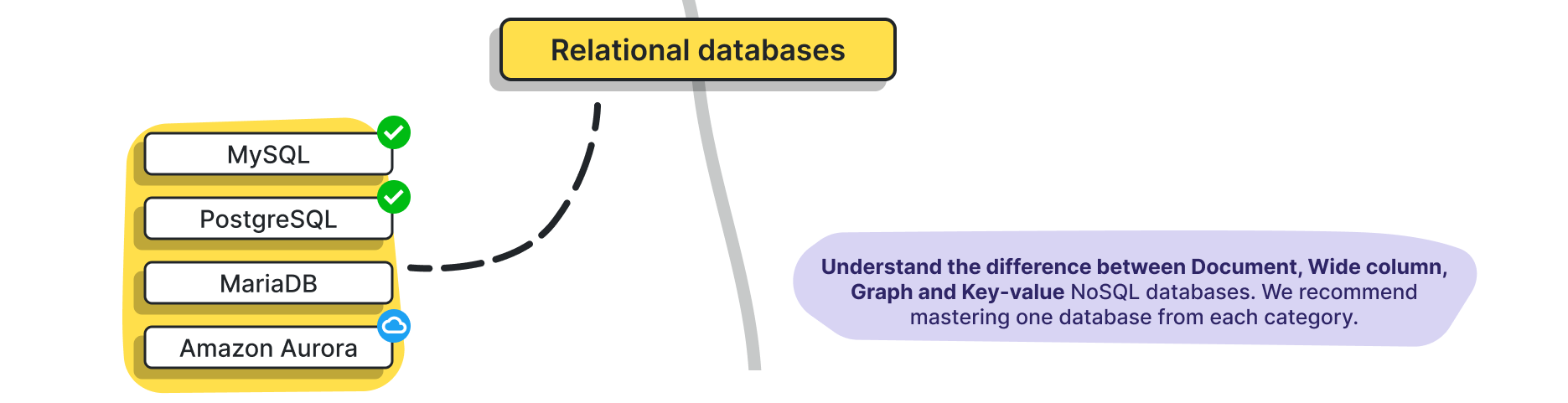
- 다양한 데이터베이스 플랫폼에 대해서 숙지 (MySQL, PostgreSQL, ...)
- 요즘은 워낙 다양한 RDBMS들이 많고, 저거 이외에도 분산 클러스터 형태의 DB 도 있어 깊이 파면 끝이 없긴 하다.
비관계형 데이터베이스 (NoSQL)
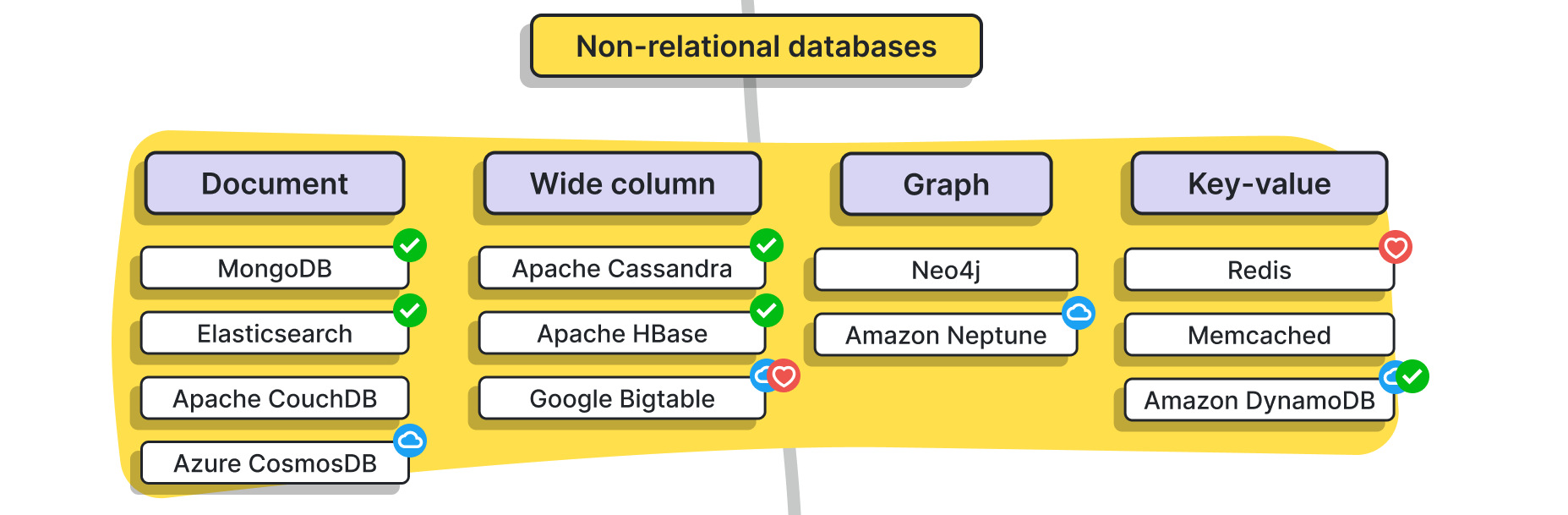
- 대용량 데이터를 저장하고 검색하긴 위한 플랫폼으로, 근래 큰 규모의 데이터 저장 시대가 도래하면서 굉장히 분류가 다양하고 종류 또한 많다 (여기 없는 것들도 수두룩하다)
- 문서: MongoDB, Elasticsearch
- 큰 테이블(wide column): HBase (apache), Cassandra, ...
- 그래프 형태: Neo4j, Amazon Neptune
- key-value 형태: Redis 등등...
- 개인적으로 이 중에서 많이 쓰이는 건 자타공인 Redis, 그 다음이 Elasticsearch/MongoDB 정도?
- 해당 DB들의 아키텍처 까지 알아두면 도움이 많이 될 것 같다.
- 요즘은 DB 자체에서 분산시스템을 지원하는 경우가 많고 아키텍처가 어느정도 공개되어 있는 경우가 많아서, 이것들을 공부하는 그 자체만으로도 도움이 많이 된다...

Data warehouses
- 약간 생소한 개념인데, 찾아보니 분석 가능한 형태로 정보들을 저장해 놓은 중앙 저장소라고 한다.
- 즉 모든 정보를 저장해두는 것이 아니라 분석할 수 있는 형태로 어느 정도 가공이 되어 있는 저장소라고 볼 수 있을 것 같다.
- Snowflake와 Hive를 많이 쓰는 것 같다. BigQuery는 잘 모르겠네.
- Hive를 보면 데이터 저장소라기 보다는 하둡환경에서의 일종의 질의도구라고 보인다. 아무래도 분석할 수 있는 형태로 질의를 하는 구조 자체를 데이터 웨어하우징이라고 일컫는 듯.
Object storage
- Object = 객체이다. 객체 저장을 위해 제공되는 서비스들을 다룰 수 있는지를 일컫는다.
- 왜 쓰는지를 알아야 한다. 기존의 통상적인 서버에서 storage 관련 서비스를 제공하는 것보다 훨씬 저렴하고 성능도 잘 나오기 때문, 즉 저장소는 분리해서 쓰라는 의도.
- 이런 점에 있어서는 CDN과 이해를 같이 하면 보다 쉬울 듯
- 대표적인 것들로 AWS S3 등...
- Storage Gateway 관련한 아키텍처 설명도 있다. https://docs.aws.amazon.com/ko_kr/storagegateway/latest/userguide/StorageGatewayConcepts.html
Cluster computing fundamentals

- 드디어 요즘 핫한 분산 컴퓨팅에 도달했다!
- 둘도 말할것도 없이 Hadoop, HDFS, MapReduce 개념이 핵심이라고 생각된다.
- 어떻게 Hadoop 플랫폼이 Scale-out에 적합한 형태로 되어 있고, 실제 데이터를 어떻게 HDFS / MapReduce에 알맞게 저장하고 처리할 수 있을지 고민해보는 것이 포인트
- 이 개념들을 보다보면 자연스럽게 밑에서 배워야 하는 개념들인 YARN, Spark 등에 도달하게 된다...
Data Processing
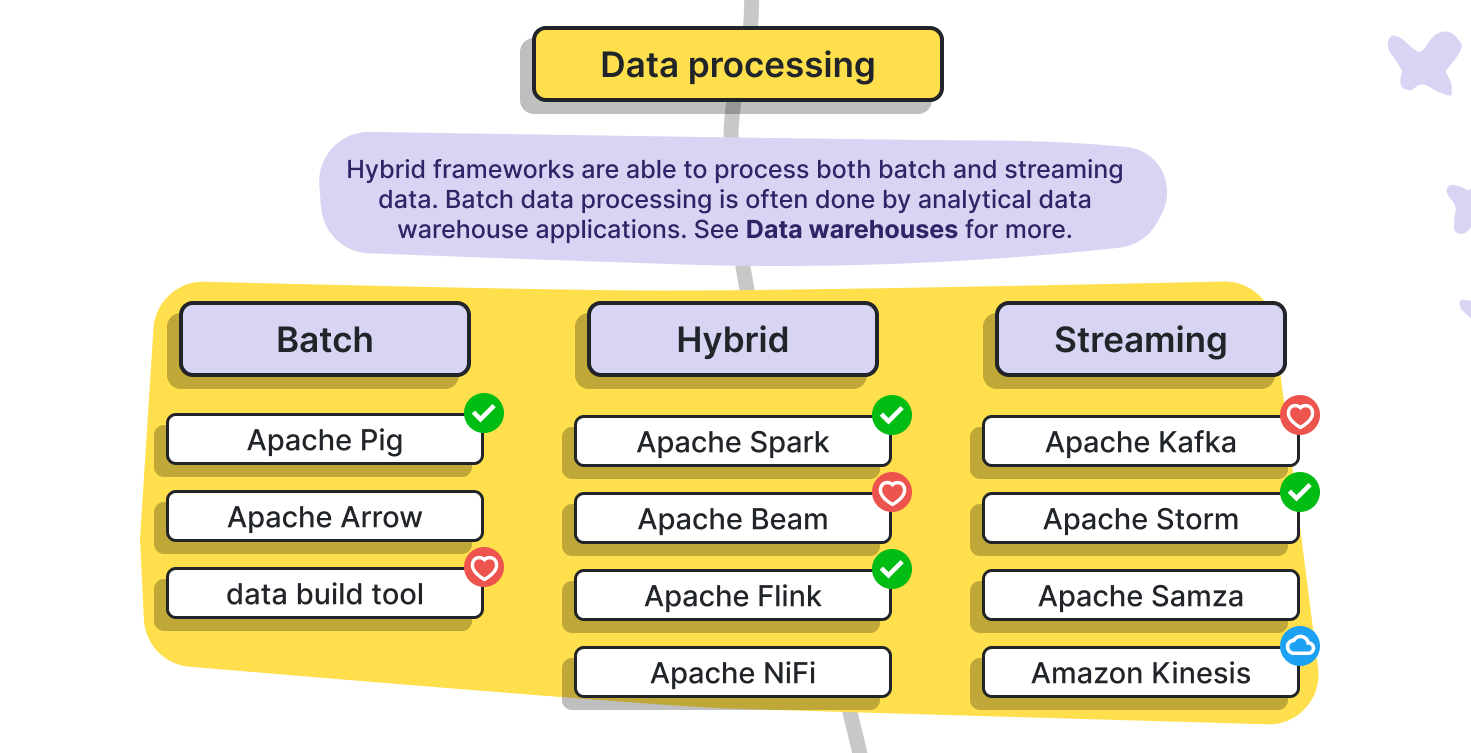
- 위의 분산 컴퓨팅에서 확장된 플랫폼들을 이야기한다.
- MapReduce와 다르게 Batch processing이 주된 핵심이고, 여기서는 Apache Spark가 절대적이라고 생각한다.
- MapReduce와 어떻게 다른지: 어떻게 process를 Batch 형태로 쪼갤 수 있을지에 대해서 고민해 볼 필요가 있음
- 등장 배경에 대해서: MapReduce의 경우에는 복잡한 배치로 사용하기에 다소 부적합, 그리고 Disk 의존성이 큰 구조이기 때문에 불필요한 I/O를 수행하게 되는 경우가 있어, 이에 대한 방안
- 근데 범주가 Batch가 아니라 Hybrid로 되어 있네. 아무래도 HDFS에서 값을 가져오니까 그런건가?
- 배치 이상으로 빠른 응답을 위한 Streaming 프로세싱에서는 Storm이 우세하다.
- Kafka는 MQ로 쓰이는 것으로 아는데, 특성상 Streaming으로도 쓰나보다. Stream에 들어가 있네
Messaging (MQ; Message Queue)
- 분산시스템에서의 메시지 큐: 빠른 속도와 정합성을 챙기는 것이 핵심 포인트
- Kafka와 RabbitMQ가 절대적이다. 두 아키텍처가 꽤 차이가 있으니 공부해두면 좋을 듯
- 정작 여기서는 Kafka를 MQ에서 빼 버렸네...
Workflow Scheduling

- 아주 간단하게 말하면 분산 시스템에서의 Worker 모델을 구현한 플랫폼이고, 구체적으로는 Work"flow"를 스케줄링하여 수행하는 플랫폼
- Workflow는 DAG 형태로 이루어져 있고, 작업을 수행하는 각 Node는 약하게 결합되어 있어 이들을 연계하게 됨.
- DAG 형태의 Workflow를 분산시스템에서 구동하면 필요한 부분은 병렬화하여 수행하므로 성능상 이점을 자연스럽게 챙길 수 있음
- 이거 이외에도 많은 플랫폼들이 또 존재하긴 하는데...
Temporal.io라던가 ... 근데 이건 정말로 Worker 모델 구현에 그쳐 있어서 여기 넣기는 좀 애매한 점이 없잖아 있네요- Hadoop YARN도 여기에 해당이 안 되는 건지 언급이 전혀 없다. IaC로 넣기에도 애매한 측면이 있고...
Monitoring data pipelines
- 분산시스템의 복잡성을 감안했을 때 로그 종합화/분석 및 이슈 트래킹요소의 중요성은 꽤 막대합니다. 해당 툴들이 어떤 문제 상황에서 어떤 일을 할 수 있는지 알고 있으면 좋을 것 같습니다.
- 보통 Prometheus 많이 쓰는 듯? 그런데 이 분야도 툴이 워낙 많이 나오는 것으로 알고 있기도 하고, 마음에 안 들면 직접 만드는 경우도 많아 확답할 수는 없고, 역시 문제상황에 대비해서 어떤 요소를 모니터링 하느냐가 포인트인듯.
Networking
- 의외로 굉장히 뒤에 나오는 내용이다... 사실 어지간한 건 플랫폼/프레임워크에서 다 지원해 주는 기능이니까 크게 비중이 없을지도?
- 아마 여기까지 이해하고 들어온 사람이라면 여기는 그닥 확인할 부분은 없을 것 같다
- 기본적인 방화벽 및 프로토콜, 라우팅 지식과 실제로 이를 UNIX 시스템 상에서 컨트롤할 수 있는 정도의 능력은 숙지하는 게 좋음
IaC; Infrastructure as Code
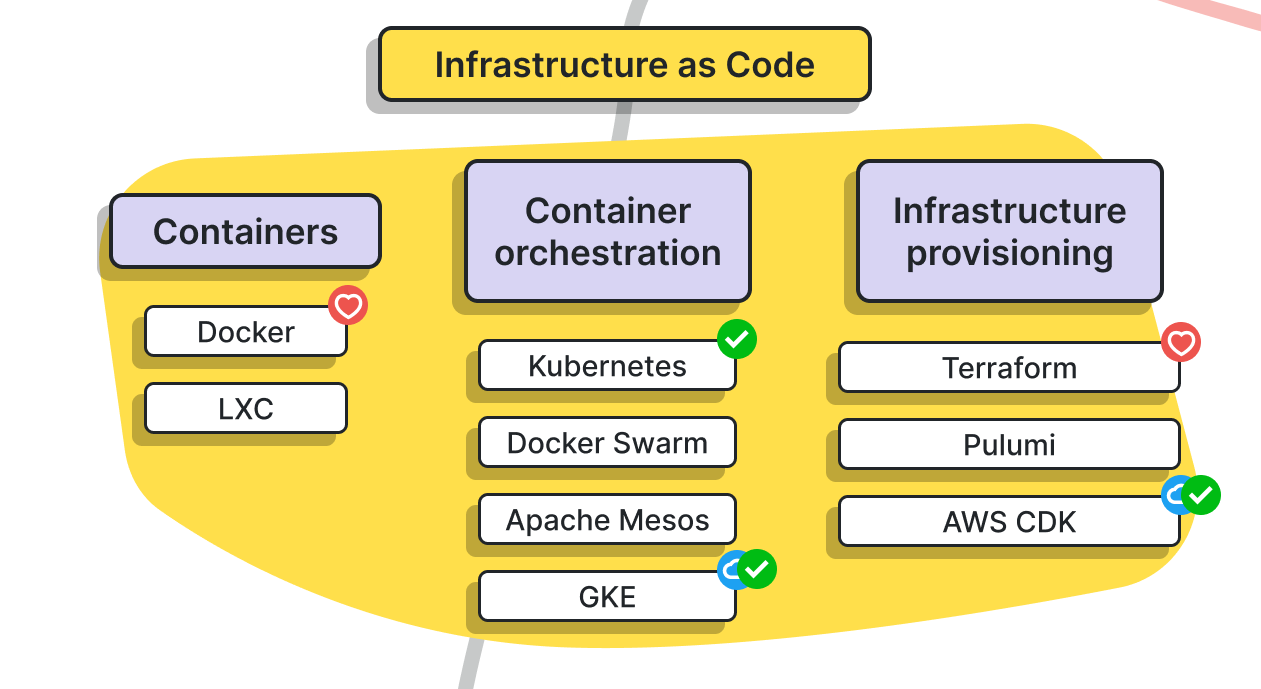
- 요즘 성행하는 Container 기술과 orchestration 기술이 포인트.
- Docker 아키텍처는 필수 숙지해야 한다고 봐야 합니다. (cgroups, namespace)
- 깊게 들어가면 UNIX/Linux 지식도 필요할 수도? 보통 이 정도까지 할 정도면 숙지 했겠죠..?
- Container orchestration은 kubernetes가 우세한데, 핵심으로 Auto-scaling 기술과 어떻게 장애상황 대처하는지를 아키텍처 숙지하며 알면 좋습니다.
- Provisioning(대충 환경 초기 구성)을 위해서는 Terraform이 우세하다 합니다. 이 부분까지는 보통 손 댈일이 잘 없어 모르겠음.
CI/CD
- 왜 이게 필요한지 알지만, 막상 실제 도입하면 어떤 문제가 발생할 수 있는지 알고 있어야 실제 구성하는 데 있어 도움이 됩니다.
- 실무 해본 사람이라면 아마 몸으로 다 알고 있을 듯..?
- 테스트 솔루션 구성, 아키텍처, 시행착오 관련해서 많은 아티클들이 있으니 찾아 읽어보면 좋습니다. 이를테면 https://engineering.linecorp.com/ko/blog/server-side-test-automation-5/
- 보통 Jenkins 많이 쓰는데 근래에는 Github Actions로 갈아타는 성향이 있다고 하는 듯. 쓰기 나름이니 이건 취향따라 고르면 되는 것 같습니다.
Identity and access management
- 보안 정책 및 사용자 계정 정보 등을 저장하고 관리하는 방식인데, 보통 안 쓰잖아요..? (...) 과감하게 패스.
- 그래도 역시 아키텍처는 소중하니 알아두면 좋겠다고 생각합니다. https://docs.microsoft.com/ko-kr/azure/active-directory/fundamentals/active-directory-architecture
Data security & privacy
- 실제 서비스하는 입장에서의 데이터 보안... 이건 보통 보안 부서가 따로 있기도 하고 해서 깊이있게 파지는 않는 것 같다 -_-; 그래도 알면 좋다.
Extra?
그래프를 보면 알겠지만 끝이 잘려 있다. 어? 미완성된 그림인가? 왜 끝이 잘려있지? 잘 보면 다음 그림이 있는데, Extra part를 다루고 있다. Data scientist 이야기이다.
아무래도 데이터를 보관하고 관리하는 엔지니어들은 특성상 Data scientist들과 같이 일할 것이 보통 기대되기 때문에, 이들이 사용하는 툴과 아키텍쳐에 대해서 어느정도 이해가 필요할 수 있다.
물론, 꼭 그렇지만은 않다. 순수 Cloud 서비스만을 한다면 데이터 과학자가 없을 테니... 하지만 보통 데이터가 있으면 데이터 과학자 수요가 자연스럽게 생기기 마련이더라...
이 부분은 워낙에 방대하기도 하고 지금 커버하는 분야와 다른점도 많아서 깊이있게 쓰려면 한참 걸리고 (그럴 능력도 안 되거니와), 간단하게 쓰자면 그래프에서 설명하는 툴킷 정도면 충분하다. 그래서 추가로 설명할 내용은 없다 ㅎㅎ.
마무리
대학원 때 Data Science 관련 일을 조금이나마 해봤던 경험을 토대로, 나는 데이터 엔지니어 그거 뭐 별거 있겠나~ 비슷한거 아닌가~ 하는 몹시 안일한 마음가짐을 가지고 있었다.
하지만 근래 Cloud 및 Data Engineering 관련 직종 이직을 도전하면서 데이터 웨어하우스 밑의 종목부터 하나도 제대로 모른다는 걸 깨닫고 열심히 공부하고 있다 ㅋㅋ. 예전에는 이런 복잡한 아키텍쳐 뭣에 쓰지? 이런 부정적인 스탠스만 취하고 있었는데, 데이터가 상상하기 어려운 수준으로 불어난 요즈음이 되니 그 필요성이 코앞까지 다가왔다. 공부해야겠다.
'개발 > Essay' 카테고리의 다른 글
| 재직 중인 회사에서 연봉 협상하기 (0) | 2022.03.01 |
|---|---|
| 코딩 인터뷰, System Design 인터뷰에서 면접관이 원하는 것 (0) | 2022.03.01 |
| 개발자의 실수와 패널티 (0) | 2022.02.26 |
| 3년차 개발자의 이직 후기 (4) | 2022.02.16 |
| 팀장으로서 1년을 보낸 후기 (0) | 2022.02.05 |