데이터의 크기가 기하급수적으로 증가하면서, 최근에는 관계형 데이터베이스(RDBMS)보다 자유롭게 데이터를 저장하고 처리하기 용이한 NoSQL이 도래하고 있습니다. RDBMS는 CRUD 및 데이터 모델링에 있어서 자유로운 모습을 보여주고 있지만, 아무래도 분산 시스템에 최적화된 모습을 보여주지는 못하는 것 같습니다. 그 방증으로 빅데이터 프로젝트에서 그 유명한 MySQL과 Oracle이 불리는 모습을 찾기가 쉽지 않다는 것입니다.
하지만 그럼에도 불구하고 RDBMS도 분산시스템 시대에 걸맞게 계속 변화해왔습니다. 의외로 그 역사가 긴데, MySQL Cluster는 2004년에 만들어졌고 Oracle RAC는 2001년 즈음에 나왔습니다. 이것들이 어떤 일을 하고, 어떤 결과를 가지고 왔는지를 정리해보려고 합니다.
CAP 이론
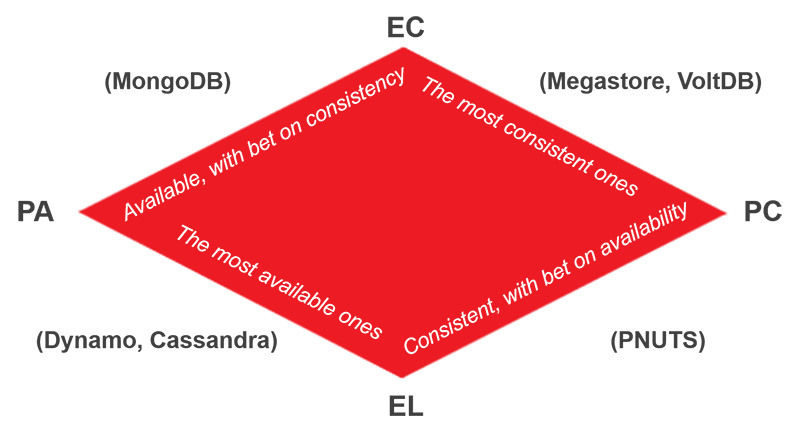
먼저 대규모 데이터 처리에 왜 RDBMS가 불리한지를 짚고 넘어가면, 이론적으로는 CAP 이론이 있습니다. 이는 어떠한 시스템도 일관성(Consistency), 가용성(Availablity), 분단 허용성(Partition tolerance) 세 가지를 동시에 만족할 수 없다는 것입니다.
RDBMS는 기본적으로는 CA 시스템입니다. 하지만 Partition 구성에서는 Availabilty를 포기하고 CP 구성으로 보통 가게 됩니다. Constraint가 많은 RDBMS 특성상 정합성이 깨지면 심각한 문제가 생길 수 있기 때문에, 대신 가용성을 포기하는 수밖에는 없게 됩니다.
언제든지 scalable하고, high availability가 중요한 분산 시스템에서는 달갑지 않은 이야기입니다. 약간의 availability를 포기할 수 있는 NoSQL이 선호되는 이유가 여기에 있습니다.
추후에는 정상/장애 상황에 대한 고려를 추가하여 PACELC 이론이 새로 생기게 됩니다. NoSQL내 분류가 여기서 또 갈리고, 입맛따라 선호하는 형태를 고를 수 있을 듯 싶습니다. 여기서는 중요한 내용은 아니니 참조용으로만 달아놓는 걸로...
{kind=link}
가용성의 증대: DB의 클러스터링
뭐, 위에서 RDBMS의 정합성에 관하여 잔뜩 겁을 주었지만, 그럼에도 불구하고 혼자 도는 것보다는 여러 노드가 같이 클러스터링 구조로 도는 게 가용성 면에서는 유리할 수밖에 없습니다.
그럼에도 불구하고 분명 가용성은 NoSQL보다는 낮습니다. 치명적인 문제가 생기면 얄짤없이 recovery process를 거쳐야 합니다...
현재로서는 Oracle RAC, MySQL 클러스터링과 같은 기술이 그러한 범주에 속합니다.
파티셔닝 (Partitioning)
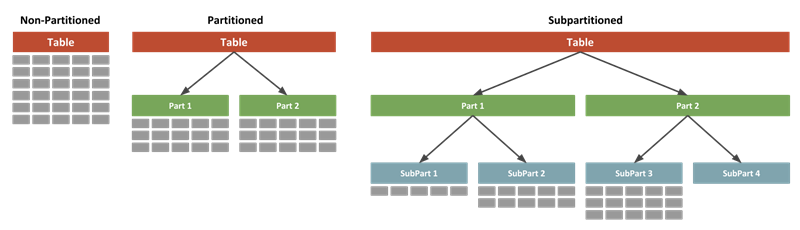
DynamoDB처럼, RDBMS에서도 partitioning을 지원합니다. Oracle 공식 문서에도 Partition 관련 내용들이 많이 언급되어 있습니다.
으레 그렇듯이, 적절한 partition key을 설정을 통해 분산처리를 꾀해서 성능 증대를 꿈꿀 수 있습니다. Partition간 Storage(Datafile)의 분리도 충분히 가능합니다. 사실 이게 NoSQL을 쓰는 가장 큰 이유 아닐까 싶습니다 ㅎㅎ...
일관성 보장: Cache Consistency
분산 시스템의 기본인 정합성을 보장하기 위해서, Cluster 간 공유 객체에 대한 Lock이나 Cache에 대한 atomic operation을 지원합니다.
보다 구체적으로는, 오라클 RAC의 경우에는 자주 사용하는 Data Block을 Buffer Cache에 올려놓는 형태로 설계가 되어 있습니다. 일반적인 Single DB Instance면 자신의 객체를 참조하는 것으로 충분하지만, Clustered DB에서는 다른 Node의 Buffered Cache에 올라와 있는 정보를 참조해야 하는 일이 발생할 수 있습니다.

이 때 Node간에 Interconnect를 수행하여 타 Node의 캐시를 참조할 수 있게 되고, 권한 설정을 하게 됩니다. 그러한 방식으로 캐시의 일관성과 효율성을 보장하게 됩니다.
그리고 이를 통해 RDBMS 특유의 방대한 관계성 스키마를 효율적으로 처리할 수 있게 됩니다. NoSQL 같은 경우는 관계성 스키마가 없고 각 데이터 하나가 독립적인 처리 단위가 되니, 이렇게 캐시를 공유할 필요성이 없게 되죠.
이미지 출처 및 보다 자세한 사항은 이 아티클 및 RAC 내부 구조에 대한 아티클 참조.
서버-사이드 데이터 처리: like Hadoop
하둡은 key-value 기반의 HDFS 파일 시스템을 기반으로 하여금 대용량 분산처리를 가능하게 하는데, 이를 가능케 한 기법 중 하나가 MapReduce입니다. 데이터 splitting을 통해 mapping을 하고, shuffling 후에 이를 묶어 처리하는 reduce를 여러 클러스터에서 동시에 수행하여 high throughput을 가능하게끔 합니다.
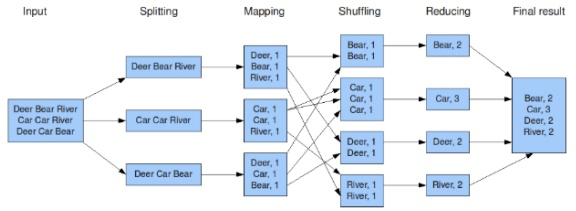
Oracle RAC 구조에서도 이와 비슷한 분산 처리 시스템을 구현할 수 있습니다. Oracle에는 PL/SQL과 같은 server-side 언어가 존재하고, 해당 언어로 UDF(User defined function)을 만든 후 이를 PARALLEL로 수행하면 각각의 클러스터가 작업을 수행하여 결과를 합산하게 됩니다.
데이터의 배치 프로세싱: like Spark
사실 이 내용은 NoSQL과는 거리가 좀 있긴 한데, 최근 빅데이터 트렌드에 부합(?)하는 효율적인 데이터 프로세싱 파이프라인 기법중 하나인 것 같아 굳이 끼워넣었습니다.
Spark는 머신러닝과 같은 무거운 작업을 배치별로 분산처리할 수 있도록 하는 플랫폼입니다.
Oracle의 경우에도 이와 비슷한 방식으로 대규모 데이터를 단계적으로 처리할 수 있게금 하는 방법을 지원합니다.
PIPELINEDTABLE FUNCTION 사용하기- PL/SQL 내에서
BULK COLLECT LIMIT 100과 같이 사용하기
그럼에도 RDBMS가 가지는 한계
그럼에도 RDBMS는 빅데이터 시대에서 크게 두각을 드러내지 못하고 있습니다. 이유가 뭘까요? 제 경험상, 저는 아래와 같은 이유라는 생각을 해 봅니다.
- 무거운 클러스터 인스턴스
- RDBMS의 기능은 막강하지만, 무겁습니다.
- 근래 대세가 된 쉽게 확장 가능한 Microservice의 정의 및 니-즈에 부합하기 어렵습니다.
- 안에서 정확히 어떤 일을 하는지 알기 어려움
- 물론, 쿼리의 구성요소가 어떤 결과를 만들어 내는지는 정확히 정의되어 있습니다.
- 하지만 RDBMS에서 사용되는 쿼리를 처리하기 위해서 내부적으로 최적화된 PP를 생성하는 작업을 하게 되는데, 이는 직접 확인해보기 전까지는 보통 알 수 없습니다.
- 즉 결과를 만들어 내기 위헤서 내부적으로 어떤 작업을 수행하게 되는지를 직관적으로 알기 어렵습니다.
- NoSQL 기반 DB들은 아키텍처가 단순하고 명확하기 때문에 쿼리 수행시 내부적으로 어떤 일이 이루어지는지를 어렵지 않게 파악할 수 있는 것에 비하면 단점이 된다고 생각합니다.
- 의도한 것과 달리 내부 구조/내부 동작이 정해져서 성능에 악영향을 끼치기도 합니다.
- 심지어 그 복잡함으로 인해 버그가 종종 발생하기도 합니다...
- 떨어지는 가용성
- 앞에서 이야기 했듯 RDBMS 특성상 가용성의 제약이 심한 편이고, 선택의 여지가 없는 점도 약점이 됩니다.
- 너무 높은 자유도 — 사용자가 비효율적인 모델을 구성하는 것을 허용함
- 자유도가 높으면 좋은 것이 아닌가? 생각할 수 있는데, 적어도 빅데이터를 다룰 때만큼은 아니라고 생각합니다. 높은 자유도는 때로는 비효율적인 모델을 사용자가 만드는 것을 허용하도록 하고, 이는 퍼포먼스 이슈로 이어집니다.
- 이를테면 중복이 몹시 심한 값을 키로 설정한다든가, 특정 파티션에 크게 경합이 일어나도록 설계하는 것을 허용하는 것 들입니다. 개발은 쉽지만, 서비스 도중 이슈가 터지게 되어 사용자 경험을 크게 저해시킬 가능성이 높습니다.
- 실제로 관련 문의가 많이 생깁니다. 왜 저렇게 스키마를 굳이 짜 놓았을까...
- 내부적으로 특정 값에 경합이 많이 생기면 클러스터간 캐시 경합도 상당히 심해지는데, 이는 크게 성능을 저해할 뿐만 아니라 원인을 분석하기도 어렵습니다. 모두가 괴로워지는 결과를 유발하죠...
- hadoop이 일부러 key-value 모델로 데이터를 저장하도록 강제하고, Amazon DynamoDB의 partition 당 record를 강제로 제한하고 있는 것 또한 같은 맥락입니다.
하지만 그럼에도 불구하고 데이터 모델링에서 RDBMS가 주는 이점을 포기할 수 없어, Greenplum과 같이 NoSQL 구조의 장점을 융합한 DBMS가 생기기도 합니다. 데이터의 규모와 용도에 맞게 적절한 선택을 할 수 있을 것 같습니다.
이 부분은 제 생각들이라 주관적 요소가 많이 들어가 있습니다 🙃. 잘못되었거나 부족한 내용은 코멘트 주시면 반영하겠습니다.
'개발 > Engineering' 카테고리의 다른 글
| Address Sanitizer과 그 원리 (0) | 2022.04.09 |
|---|---|
| Rolling Update (0) | 2022.03.13 |
| GNU Parallel과 Pipe (0) | 2022.03.01 |
| 맨먼스 미신, 개발자의 생산성에 관하여 (0) | 2022.02.27 |
| 게임에서의 소프트웨어 디자인 패턴 (0) | 2022.02.25 |