
Go는 GC가 알아서 메모리를 관리해주는 편한 언어입니다. 개발자가 할당한 메모리를 깜빡하고 내버려두는 바람에 누수될 일은 거의 없다는 이야기이죠.
물론, 반대급부로 어느 정도의 (성능과) 메모리 사용량을 감수해야 합니다. Go vs. Rust 테스트를 한 이 글만 보아도 그 차이는 확연하게 드러납니다.
그렇다고 그것이 Go를 포기할 이유가 될 수 있을까요? 언어가 주는 성능도 중요하지만 생산성 측면도 무시할 수 없는 요소입니다. 그리고, 더 중요한 것은 메모리를 많이 쓰는 요인이 잘못 만든 코드 때문일 수 있다는 점을 간과해서는 안 됩니다. Go에 최적화되지 않은 코드, GC 대상이 아니지만 전역 리스트에 저장되어 할당이 해제되지 않아 발생하는 메모리 누수, reservation 없는 비효율적인 리스트 관리 등 원인을 먼저 확인할 필요가 있습니다.
그러한 관점으로 좋은 글이 있어 읽고 정리해 둡니다.
- 이 포스트는 Akita의 포스트를 (대충) 번역했습니다: Taming Go’s Memory Usage, or How We Avoided Rewriting Our Client in Rust
몇달 전 많은 스타트업들이 마주하는 의문에 맞닥뜨린 적이 있습니다: “우리 Rust로 다시 코드 짜야 하나..?”
당시 우리는 Go + Python 언어를 기반으로 API 트래픽을 분석하는 기능을 만들었습니다. 고객들은 우리가 만든 에이전트를 통해 API 트래픽 데이터를 우리의 클라우드로 보내고, 우리는 그것을 분석하는 작업을 합니다. 그런데 고객의 트래픽이 더 많이 발생하게 되었는데 — 고객들이 불만을 표하기 시작합니다: “에이전트가 메모리를 너무 먹어요”
이 문제 덕분에 25일동안 좌절감을 맛보며, Go의 메모리 관리에 대해서 열심히 공부하며 메모리 사용량을 수용 가능한 수준까지 내리기 위해 힘썼습니다. Go의 GC 가 완벽하지는 않기 때문에, 쉬운 일은 아니었죠.
특히 이 작업 관련해서 참조할 만한 글이 많지 않았기 때문에, 이 과정을 글로 남기면 좋을 것이라는 생각이 들었습니다. 다른 사람들도 이 글을 읽고 Go의 메모리 사용량 추적할 때 도움을 받길 바래요!
발단
Akita CLI 에이전트는 API 트래픽을 감시합니다. 그리고 이는 protobuf 포멧으로 변환되어 Akita cloud로 전송되고, 혹은 내부적 사용을 위해 HAR 파일로 캡쳐하곤 합니다. 그리고 점차 CLI 개발을 담당하게 되면서, Go 언어 및 GoPacket를 사용하여 패킷 캡쳐를 하게 되었습니다. 이는 다른 TCP 코드를 가져다 쓰거나 하는 일보다 훨씬 편해서 좋았습니다. 그러나, 막상 우리가 트래픽을 실제 환경에서 캡쳐하게 되자, 에이전트의 메모리 사용량이 점차 중요해지게 되었습니다.
그러던 어느날, 평상시 잘 작동하는 에이전트가 갑자기 기가바이트 단위의 메모리를 먹는 것을 확인하게 되었습니다.
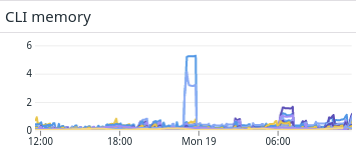
고객에게서 이 이야기를 듣고 나서 해야 할 일은 명백했습니다. 메모리 사용량을 줄여야죠! 적어도 다른 collection agent인 DataDog 같은 수준으로 줄여야 합니다.
이건 Go의 제약 때문에 쉽지 않은 일이었는데, 왜냐하면 Go의 GC는 Non-generation, Non-compacting, 동세대 mark-and-sweep 특징이 있었기 때문입니다. 덕분에 STW도 없고 속도도 빨라서 좋긴 한데, 역으로 말하면 이러한 GC를 통제할 요소가 파라미터 단 하나밖에 없다는 말입니다: SetGCPercent . 이걸 줄이면 GC를 더 자주해서, CPU를 조금 더 자주 쓰는 대신 메모리를 아낄 수 있겠죠. 그리고 Go의 배열 — Slice나 Map 같은 것 — 은 기본적으로 많은 메모리를 요구하는데, 만들기가 쉬운 특성 때문이죠. (= 우리가 내부 동작에 대해서 관여할 수 없어 편하지만, 역으로 더 효율적인 구조로 사용하게 만드는 것도 불가능합니다)
C++로 개발할 때에도 메모리 스파이크는 큰 문제였지만, 그래도 대처할 수 있는 방법은 생각해 보면 많았습니다. 예를 들면, 메모리 할당을 특화시키거나 제한시켜서 통제할 수 있었죠. 심지어는 일부 패킷을 빼버린다던가 하는 식으로 어떻게든 대처할 수 있었습니다.
Java에서도 비슷한 문제를 겪은 적이 있는데, 그래도 Java의 경우에는 Heap 메모리 사용량에 대한 풍부한 정보를 제공받을 수 있었고, GC에 대해서 상세 설정을 해줄 수 있었습니다. 생각해보니 최대 메모리 사용량을 강제할 수 있는 옵션도 있었는데, 그거라도 있었으면 차라리 좋았을 것 같다는 생각이 드네요.
그런데 지금 같은 경우는, Go의 GC가 언제 어떻게 도는지를 알 수가 없는게 문제입니다. 그렇다고 메모리 할당을 중앙집중형으로 통제할 수도 없고요. 일단 두가지 선택지가 있었지만, 쉽지 않은 것이 문제입니다:
- 사용중인 객체의 메모리 사용량을 줄이자
실제 사용중인 메모리 객체들은 GC 될 수 없으니, 일단 이 친구들이라도 어떻게 해볼 필요가 있습니다. - 메모리 할당 횟수 자체를 줄이자
Go는 프로그램이 실행되는 도중에 성능을 최대화하며 GC를 수행합니다. 하지만 이것이 메모리 할당을 일시적으로 늘리는 문제도 있거니와, 사용하는 힙 사이즈도 증가시킵니다. 즉 메모리를 희생하여 속도를 챙기는 경향이 있습니다.
직접 확인을 위해, 이러한 방면으로 고칠 부분이 있는지 CLI 에이전트를 확인해보기로 했습니다.
1 — 사용중인 객체의 메모리 사용량 줄이기
일단 Go heap profiler로 메모리 사용량을 확인해 봤는데, 바로 보이는 reassembly buffer 이놈이 몹시 수상합니다.

앞서 말했듯이 우리는 Gopacket를 사용해서 트래픽을 캡처하고 처리한다고 하기로 했죠. Gopacket는 보통 문제 없이 잘 돌아가지만, TCP 패킷이 비순차적으로 도착할 경우, 이것들을 reassembly buffer에 담게 되어 있습니다. 그리고 reassembly 코드는 페이지 캐시로부터 이 버퍼 메모리를 할당받아서 계속 들고 있게 됩니다: 그렇기 때문에 할당받은 메모리를 돌려주는 일이 없죠.
우리는 첫 번째로, 호스트에게서 전달받은 패킷 중, 캡쳐되지 않은 패킷들이 영구적으로 메모리를 왕창 잡아먹는 게 아닐까 추측했습니다. Gopacket가 비순차적 패킷을 저장하기 때문이니까요. HTTP는 지속적인 커넥션(persistent connection)을 사용할 수 있고, 이 경우면 몇 기가바이트의 패킷이 전송되는 걸 다 저장해버리는 상황을 가정할 수도 있습니다. (Gopacket는 retransmission이 일어날지도 모르니 패킷을 다 가지고 있지만, 그럴 일은 없겠죠?)

사실 우리는 Gopacket에 패킷 Timeout을 설정하도록 했습니다. 하지만 너무 길게 설정해 버린 탓에, 속도가 빠른 데이터 전송의 경우에서는 이런 문제가 발생해 버리게 되죠. 그리고 Gopacket에서 캡쳐할 수 있는 패킷 메모리 제한량도 설정을 해두지 않았습니다.
적당한 값을 찾기 위해서, 우리는 실제 데이터 전송에서 문제가 없을 수준이 되는지를 우리 시스템에서 직접 확인해보았습니다. 일단 75MB/s, 40초 전송의 경우 3GB의 메모리를 점유하게 되는데, 그정도 데이터 전송의 경우 7.5MB의 메모리 만으로도 100ms의 왕복 시간 동안의 데이터를 보장할 수 있습니다. 그래서, 우리는 Gopacket이 최대 커넥션당 4000page의 메모리를 사용하도록 설정했고, 총합 150000 페이지까지를 허용하도록 했습니다. 약 200MB네요.
불행히도 200MB 만을 전역 한도치로 쓸 수는 없었습니다. CLI 에이전트가 네트워크 인터페이스마다 붙는 까닭이었죠. 궁극적으로 이에 대한 해결방안을 찾지는 못했지만, 200MB의 공간을 에이전트끼리 동적으로 나눠 쓰는 정도로 처리했습니다.
그리고 Gopacket 버전도 업그레이드 했습니다. 새 버전에서는 reassembly 버퍼를 sync.Pool 에서 할당받는데, 이 클래스는 free list 처럼 사용할 수 있지만 안에 들어있는 요소들은 GC에 의해 정리될 수 있었죠. 최악의 경우에서는 별 차이가 없다지만, 평균적 메모리 사용량을 낮추는 데에 도움이 됨은 확실했습니다.
덕분에 5GiB의 끔찍했던 메모리 사용량에서 상당히 줄였지만, 여전히 1GiB 스파이크 사용량은 너무 많았습니다.
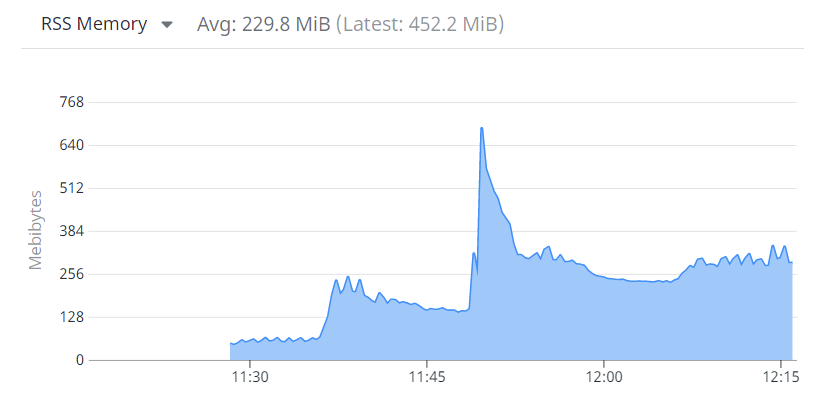
DataDog로 이것저것 해보다 보니, 이러한 순간적인 메모리 사용량 증가는 incoming API traffic의 급증과 연관이 있다는 것을 알아냈습니다.
메모리 커스터마이징 옵션
고객들이 메모리 사용량을 더 통제할 수 있도록, 우리는 네트워크 처리 파라미터들을 CLI로 설정할 수 있도록 만들어 놨습니다. 예를 들면 --gopacket-pages 를 통해 페이지 캐시 최대 크기를 정한다던가, --go-packet-per-conn 을 통해서 단일 TCP 연결이 최대 사용할 수 있는 메모리 크기를 통제한다던가 하는 식으로요.
그리고 stream timeout도 설정할 수 있도록 했고, 최대 http request 페이로드를 설정할 수 있는 옵션도 만들어 두었습니다.
2— 임시 객체의 메모리 사용량 줄이기
버퍼를 고친 것만으로는 메모리 사용량 문제가 충분히 해결된 것 같지 않아서, 더 점검해보기로 했습니다. 메모리 prof를 찍어 보았지만, 별달리 누수가 보이지는 않네요.
사실 우리의 CLI 에이전트가 메모리를 몇기가씩 먹어도, 막상 프로파일을 찍어서 확인되는 힙 메모리 사용내역에서는 별달리 문제를 확인할 수 없었습니다. Go의 GC가 대략 존재하는 객체들의 두배 쯤의 메모리를 먹도록 설정된 것으로 보이고, 덕분에 Go를 고른 게 걸림돌이 된 셈이죠.
아무래도 관점을 달리 해서 Total Allocation을 볼 때가 되었습니다. 다행히도 Go의 heap profiler에서는 같은 덤프 안에 메모리 전체 할당 내역을 저장해두고 있어, 메모리를 왕창 먹는 지점을 찾아낼 수 있었습니다. 아래 짤 처럼요. (also available in this Gist)
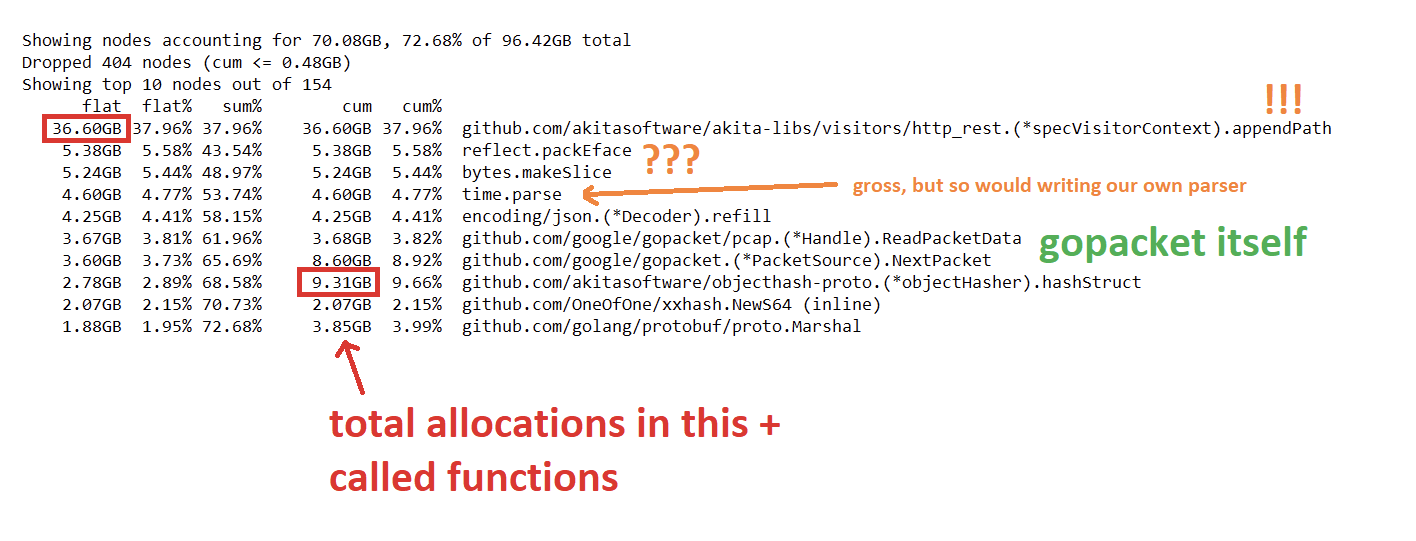
반복되는 정규식 컴파일
반복되는 작업(할당, 초기화)은 밖으로 빼 놓읍시다
heap profile 중, regexp.compile 객체에서 거진 30% 가까운 메모리 할당을 보여주고 있었습니다. 우리는 데이터 포멧을 확인하기 위해 정규식을 사용하곤 하는데, 그 안에서 매번마다 정규식을 컴파일하고 있었습니다.

컴파일을 한번만 할 수 있도록 정규식을 모듈 레벨로 옮기는 건 어렵지 않은 일이죠. 이를 통해 매번 정규식을 컴파일 할 필요도, 임시 할당 횟수 또한 줄일 수 있었습니다.
이건 정말 찾기 힘들었는데, 왜냐하면 메모리 덤프를 떨궈도 처음과 끝 사이에서 메모리 사용량 변화를 찾는 것은 어려운 일이었기 때문입니다. 우리는 메모리 사용량 스파이크를 찾고자 했기 때문에, 원하는 대로 재현하는 게 쉽지 않았고, 열심히 부하 테스트를 돌렸죠.
방문자 컨텍스트 (Visitor Context)
자주 할당되는 배열은 미리 크게 할당해 놓으세요!
임시 표현(Intermediate Representation; IR)을 위해 우리는 리퀘스트와 응답에 방문자 컨텍스트 (Visitor context)를 사용했습니다. 가장 먼저 context 객체들을 메모리 할당(생성) 합니다. Visitor 패턴이 재귀호출을 하기 때문에, 우리는 이를 간단한 preallocated stack으로 구현할 수 있었습니다. 우리가 IR에서 한단계 더 깊이 들어가면, 이를 위한 새로운 엔트리를 할당하는 방식이죠 (그 엔트리를 다 쓰면 추가 할당 하고요). 덕분에 백번 할 할당 작업을 한두번으로 끝낼 수 있었습니다.
이전에는 27.1%의 할당을 했더라면, 코드를 바꾼 이후에는 단 동일 작업에 4.36%만 메모리를 사용하는 걸 확인할 수 있었습니다. 단 이렇게 변화가 컸음에도 불구하고, 절대적인 변화가 아주 크지는 않았습니다. 메모리 할당이 다른 곳으로 옮겨갔기 때문이죠.
// before
flat flat% sum% cum cum%
7562.56MB 27.14% 27.14% 7562.56MB 27.14% github.com/akitasoftware/akita-libs/visitors/http_rest.stackVisitorContext.appendPath
// after
flat flat% sum% cum cum%
1225.56MB 5.99% 23.87% 2439.59MB 11.93% github.com/akitasoftware/akita-libs/visitors/http_rest.stackVisitorContext.EnterStruct
892.03MB 4.36% 33.36% 892.03MB 4.36% github.com/akitasoftware/akita-libs/visitors/http_rest.stackVisitorContext.appendPathgo tool pprof 를 granularity=lines 로 바꾸면 function 단위가 아니라 매 줄마다의 메모리 할당 횟수를 보여줍니다. 이걸 통해서 appendPath 에서 숨겨져 있던 메모리 할당을 찾아낼 수 있었습니다. 미리 메모리를 할당해 두는 것이 아니라 필요할 때 할당할 수 있도록 바꿀 수 있었습니다.
궁극적으로 메모리를 많이 아끼지는 못했지만, 역으로 말하면 GC가 일을 잘 하고 있다고도 할 수 있죠. 어떻게 보면 GC에게 일을 덜 시킴으로서 CPU 사용량을 아낄 수 있는 것도 이점일지도 모릅니다.
해싱 (Hashing)
오픈소스를 믿지 마세요!
우리는 중간 표현을 위해 해시 라이브러리(https://github.com/deepmind/objecthash-proto) 를 사용했습니다. 이 해시들은 오브젝트 복제 및 인덱싱을 위해서 사용되었죠. 우리는 앞서 이게 CPU를 많이 잡아먹는 건 알고 있었지만, 이제 보니 메모리도 많이 잡아먹는 걸 확인할 수 있었습니다. 이미 같은 오브젝트에 대해 해싱을 반복하지 않도록 하는 최적화는 진행했지만, 그럼에도 불구하고 여전히 많은 자원(CPU/메모리)를 소모하고 있었죠. 해싱을 하지 않으려면 재설계를 해야 할 참인데, 난감했습니다.
해싱 라이브러리 내에서는 몇몇 주요 메모리 할당이 일어나는 부분이 있습니다. objecthash-proto 는 protobuf에 내용을 채우기 위해 reflection 을 사용하는데, 일부 reflection 메서드는 멤리를 할당합니다 (일례로 reflect.packEface). 또 다른 문제는 hash 구조체가 일관성 있기 위해 key hash로 정렬을 합니다. 이 또한 bytes.makeSlice 메모리 할당으로 프로파일에 잡히게 만드는 요인이죠. 그리고 우리는 많은 구조체를 사용합니다! 마지막 문제는 objecthash-proto 가 모든 protobuf를 해싱 하기도 전에 byte로 만들어 버린다는 건데(marshal), 단지 valid를 확인하기 위해서 이 일을 합니다. 완전한 메모리 낭비입니다.
문제점을 파악하고 나니, 아무래도 우리의 구조체에 특화된 해싱 함수를 만들 필요가 있었습니다. objecthash-proto 의 장점은 어떠한 구조체에도 잘 쓸 수 있다는 것이었지만, 우리는 아무래도 IR만 잘 해싱할 수 있으면 됐으니까... 일단 같은 해싱 결과를 보여주도록 하되, 더 효율적으로 작동할 수 있도록 아래처럼 만들었습니다.
- 모든 키 해시를 미리 계산하고 인덱스로 엮어 놓음.
- 필드를 정렬된 순서대로 방문하도록 만들어놓음 ⇒ 굳이 sorting 안 해도 되게 함.
- 모든 필드를 직접 접근하도록 함 ⇒ reflect 안 씀
이를 통해서 메모리 사용량을 낮출 수 있었고, objecthash-proto 안에서 사용하던 https://github.com/OneOfOne/xxhash 라이브러리만 가져다 쓰는 것으로 충분히 구현할 수 있었습니다.
이 모든 작업을 통해 최종적으로 에이전트의 메모리 사용량을 눈에 띄게 최적화 할 수 있었습니다.
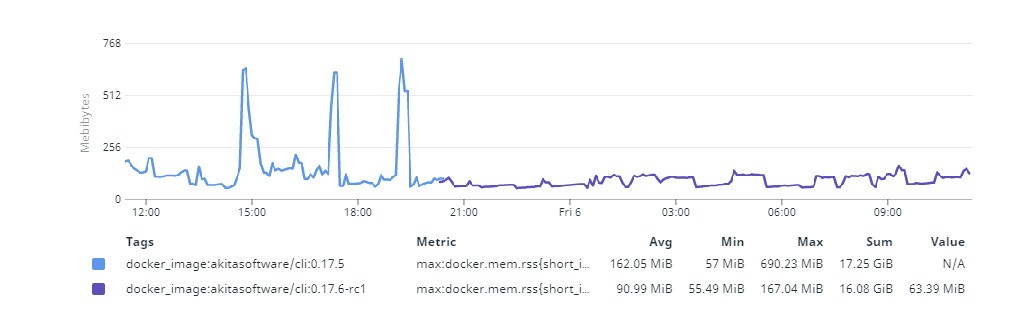
압축 해제된 데이터에 대한 임시 저장공간
아직 끝나지 않았습니다. 이 작업 내내 나는 힙 프로파일러가 “Go가 Heap 공간을 늘려버리기 전에, 어떤 allocation이 발생했는지 알 수 없을까?” 에 대한 정보를 알고 싶었습니다. 그러다가 이에 대해 좋은 아이디어가 떠올랐습니다.
대부분의 경우 이러한 힙 메모리 할당을 유발하는 것은 이미 존재하는(영속적인) 오브젝트가 아닌 “임시 오브젝트" 들이었습니다. 내 짐작을 확인하기 위해서, 실제 에이전트로부터 90초마다 힙 프로파일러 정보를 긁어와서 확인해 보았습니다.
그러다 메모리 사용량에서 스파이크를 발견하면, 바로 이전 trace를 참조할 수 있었습니다. pprof 툴을 이용하면 difference를 확인해 볼 수 있죠. 확인해보니, 하나가 메모리를 왕창 먹고 있었습니다.
Showing nodes accounting for 419.70MB, 87.98% of 477.03MB total
Dropped 129 nodes (cum <= 2.39MB)
Showing top 10 nodes out of 114
flat flat% sum% cum cum%
231.14MB 48.45% 48.45% 234.14MB 49.08% io.ReadAll
52.93MB 11.10% 59.55% 53.43MB 11.20% github.com/google/gopacket/pcap.(*Handle).ReadPacketData
51.45MB 10.79% 70.33% 123.88MB 25.97% github.com/google/gopacket.(*PacketSource).NextPacket
42.42MB 8.89% 79.23% 42.42MB 8.89% bytes.makeSliceio.ReadAll 에 대해서 콜스택을 확인해 보았는데, 이는 parser에 들어갈 데이터의 압축을 해제하는 과정에서 할당된 공간이었다는 것을 알 수 있었습니다. 이미 HTTP의 최대 전달 용량을 10MB로 제한해 놨기에, 갑자기 200MB의 공간 할당이 튀어나온 건 꽤나 놀라운 일이었죠. 하지만 그건 compressed size에 대한 제한이었다는 것을 생각하지 못하고 있었습니다.
이 문제를 해결하기 위해 두 가지의 방안이 있습니다.
- 데이터를
[]byte버퍼를 사용하지 않고 바로 파서 Reader로 읽어들이도록 함 - (분석할 수 없을만큼 큰 데이터는 어차피 이미 제한을 걸어뒀기 때문에 여기서는 논외로 함)
그런데 그러면 한 가지 방안 아닌가? 굳이 두가지 방안이라고 쓸 필요가...
Rust로 갈아 탔어야 했을까..?
이러한 개선을 했음에도 불구하고, 우리 팀은 코드를 Rust로 다시 짜야 하나 고민한 순간도 있었습니다. 메모리에 대해서 완벽한 통제를 할 수 있으니까요.
우리의 Rust에 대한 관점은 아래와 같았습니다.
- 장점!
- Rust로 메모리 관리 자유롭게 할 수 있음
- 힙스터들에게 인기 많어~ (ㅎㅎ)
- 잘 만들어진 언어에 잘 만들어진 오류 메시지.
- 단점!
- Rust는 수동으로 메모리 관리해야 해서, 메모리 관리 로직부터 다시 짜야 함
- 이미 코드가 Go로 잔뜩 짜여져 있는데, 다 고치려면 당장 시간 많이 듬
- 러닝 커브가 겁나 크다!
농담이 아니라 진짜로 “Rust rewrite 현상”이 꽤 만연해 있습니다. 각종 스타트업 포스팅이나 블로그 포스팅들에서도 Rust rewrite 글을 어렵지 않게 찾아볼 수 있죠.

결국 마지막엔 Go에서의 메모리 사용량을 조절할 수 있었고, 새로운 기능 개발에 집중할 수 있었습니다. 다만 만약 Go가 아니라 Python으로 에이전트를 개발했더라면 이야기가 조금 달랐겠죠. 하지만 Go는 충분히 low-level 언어라고 봅니다.
지금은 어떻게 되고 있나...
현재는 적은 메모리 사용량으로 고부하 환경에서 데이터를 잘 긁어오고 있습니다. 우리의 개발환경에서는 99%의 경우 메모리 사용량은 200MB 아래이고, 99.9% 경우 280MB 아래입니다. Rust로 다시 프로그램을 작성하지도 않았고, 몇달간 별 문제도 없었죠.

이러한 개선점은 우리 Akita CLI 에이전트에 해당하는 특수한 요소들이 다소 있지만, 얻을 수 있었던 교훈들은 모두에게 도움이 될 거라고 생각합니다.
- 사용하는 객체의 양부터 줄이세요. Go의 GC는 사용하는 객체는 건드리지 않으니까요.
- Allocation Profile을 해봅시다. 이를 통해 Go의 GC가 실제로 어디서 작동했는지 알 수 있고, spike가 일어나는 지점도 그 즈음일 가능성이 높습니다.
- Buffer을 사용하기 보다는 Stream 방식으로. output을 쌓아두는 건 좋지 않습니다. 아마 모든 작업이 끝날때까지 메모리를 계속 들고 있을지도 모릅니다.
- 수상하게 메모리를 먹어대는 라이브러리 사용을 피하세요. reflection 라이브러리는 강력한 기능이지만 값비싼 비용을 치러야 합니다.
뭐 Rust로 코드를 만든 것보다야 성능이 좋지는 않다지만, 확실히 이전보단 훨씬 나아졌습니다. GC를 사용하는 언어에서도 메모리 사용량에 대해서 파악하는 것은 중요한 기술이라는 걸 다시금 느낍니다!
도보시오
- How I investigated memory leaks in Go using pprof on a large codebase
- Go의 Heap 메모리를 pprof로 추출하고 분석하는 방법을 실제 예를 통해 구체적으로 설명해 주었습니다.
- 나머지 내용 절반은 메모리 누수 관련 트러블슈팅인데, 이 내용도 재밌어서 나중에 기회가 되면 정리해 놓고 싶네요.
간단히 정리하면, nodefraction=0 으로 전체 메모리 누수 내역을 확인해 본 것, 그리고 map 대신 slice를 활용하여 임시 메모리 할당을 지양한 점이 포인트겠네요. (sparse 메모리 할당 지양)
- Parsing JSON and CSV’s with Go at scale
- 메모리 할당을 줄이기 위해 csv 전환 및 동적할당을 줄이는 코드 디자인을 한 것도 인상깊지만, 다양한 방식으로 메모리 프로파일링 보는 것도 꽤 좋습니다.
'개발 > Engineering' 카테고리의 다른 글
| 왜 ElasticSearch 인가? (0) | 2022.04.30 |
|---|---|
| 문자열에 대한 철학 — Go, Rust (0) | 2022.04.28 |
| Nginx가 고가용성을 유지하는 방법? (0) | 2022.04.25 |
| Django는 과연 무거운가? (0) | 2022.04.23 |
| Kafka는 어떻게 고성능을 달성하는가? (0) | 2022.04.23 |