
프로그래밍을 처음 입문할 때 가장 이해하기 어려운 내용 중 하나가 아마 문자열 자료구조가 아닐까 싶습니다. 왜냐하면 변수에 바로 접근하여 사용하는 정수나 실수와는 달리, 문자열은 포인터를 가지고 처리한다는 점이 직관적이지 않다는 것 때문일 겁니다.
그러한 점 때문에 익숙해지더라도 올바르게 쓰기 쉽지 않은 자료구조형이기도 합니다. 문자열 할당하고 깜빡했다가는 메모리 누수가 나기 마련이거나, 잘못 쓰면 프로그램이 꺼질 수도 있습니다.
이러한 상황에서, 최근의 언어에서는 문자열을 어떤 관점으로 보고 있는지에 대해 정리해 보았습니다.
문자열의 내부 자료구조
전통적 언어에서 (C/C++)
문자열은 대개 메모리에서 일련의 연속된 byte array로 제공되고, 그 마지막에는 NULL byte가 들어가 있는 형태로 되어 있습니다. 마지막에 있는 NULL byte를 보고 나서야, 컴퓨터는 비로소 문자열의 끝을 파악할 수 있게 됩니다.
“Hello”라는 문자열을 예로 들면, 아래와 같은 형태가 되겠죠.

물론 이 경우는 간단한 ANSI 문자열 기준이고, UTF-8, 16과 같은 인코딩에서는 좀 더 복잡해지겠죠..?
이러한 관점의 문자열 관리 방식을 PWSZ (Pointer to Wide-character String, Zero-terminated) 이라고 합니다. 하지만 여기에는 고질적인 몇 가지 문제가 있습니다.
- 문자열은 무조건 문자열의 첫번째 바이트를 가리키고 있어야 함.
사실 정확히는 문자열의 중간부터 전달해도 되긴 하지만, 적어도 문자열의 중간에서 끝맺을수는 없습니다. 예를들면 “He”만 떼어서 전달할 수 없는데, 그렇게 하려면 본래 문자열을 “He\0lo\0” 꼴로 수정해야 되니까요. - 문자열의 길이를 계산하는 데 시간이 수행됨
strlen의 수행 복잡도는 문자열의 길이에 비례하게 됩니다. 문자열의 길이를 얻어오는 것 자체는 자주 하는 행위인데, 이런 구조에서는 캐시하지 않으면 상당히 비효율적이겠죠. - 안정성의 문제: Terminate 문자가 없으면 프로그램의 잘못된 결과 초래
문자열의 끝맺음 문자가 없으면 프로그램은 끝맺음 문자를 찾을때까지 메모리를 계속 뒤질 수밖에 없습니다. 그러다가 잘못된 메모리를 읽거나 쓰고 프로그램은 치명적인 오류를 맞이할 수 있습니다. - 보안 문제: 버퍼 오버런
문자열의 길이가 정해져 있지 않다는 점 때문에, 사용자가 악의적인 목적으로 긴 문자열을 넣어서 버퍼 오버플로우를 발생시키고 프로그램을 종료시키거나, 심지어는 바이러스를 침투시킬수도 있습니다.
다른것보다 안정성/보안에서 치명적인 문제를 초래할 수 있다는 것이 제일 큰 문제라고 볼 수 있습니다. 그래서 strnlen, strncmp, strncpy 와 같이 최대 문자열 길이를 설정할 수 있는 함수들이 등장하게 됩니다. 최대한으로 안정성을 보장해보기 위한 시도인 것이죠. 어찌어찌 문제를 해결했다고는 하지만, 각종 인터페이스와 함수들의 사용법은 더욱 복잡해져만 갑니다.
최근의 언어에서 (.NET, Go, Rust 등)
문자열들은 길이를 가지고 있습니다. 메모리상의 구조를 나타내면 아래와 같게 됩니다.

이러한 구조를 BSTR (Basic string or binary string) 이라고 합니다. 이러한 구조가 가지는 특징 PSWZ 대비 명백합니다.
- 문자열의 중간을 떼어서 포인터로 가르키는 것이 가능
요즘 많은 언어들에서 보이는slice라는 객체가 이런 식으로 구현되어 있습니다.
복사하고 메모리를 다시 할당하는 일이 없어 편리하고 효율적입니다. - 문자열의 길이를 가져오는 비용이 상수값
문자열의 길이를 계산하지 않고 가져오므로 자유롭게 길이 값을 호출할 수 있습니다. - 안정성 및 보안 문제에서 자유로움
NULL 문자가 없어도 문자열의 끝을 파악할 수 있기 때문에, 관련 문제에서 대부분 자유롭습니다
앞에 length 필드가 추가로 있기 때문에 메모리를 4byte(64-bit라면 8byte) 더 차지할 수 있지만, 어차피 문자열 필드는 메모리를 많이 소모하는 특징이 있고, 더군다나 요즘 거대해진 시스템의 메모리를 감안해보면 이정도 투자는 나쁘지 않다고 생각됩니다. 오히려 slice 객체를 사용함으로서 자원을 더 아낄수 있지 않을까요?
Shallow Copy
앞서 이야기했듯이, 문자열의 일부분을 가리키는 것은 문자열 값의 복사를 요구하지 않습니다. 문자열의 시작점과 길이만 알면 되기 때문이죠. 이렇게 실제 복사를 수행하지 않았지만 복제된 객체를 표현하는 것을 Shallow copy라고 합니다. 그러나, 이론상으로는 완벽하지만 실 사용에서는 여러 예외 상황들이 발생할 수 있습니다.
GC기반의 언어에서
하지만 GC 기반의 언어에서는, slice를 사용하면 곤란할 수 있습니다. 한번 아래와 같은 경우를 생각해 봅시다.
func test() string {
str1 := "This is original string"
str2 := str1[8:]
return str2
}test() 함수는 str2 = “original string”을 가지는 문자열을 리턴해야 합니다. 그런데 str2가 가리키는 메모리는 str1 이 가리키는 문자열 데이터입니다. 그런데 test() 함수의 수행이 끝나면, str1은 정리되게 됩니다. 참조하는 객체가 없거든요. 그러면 Str2는 쓰레기 메모리 포인터를 가리키게 됩니다!
따라서, slice가 특정 문자열을 가리키는 경우에서는 slice도 본래 문자열의 메모리에 대한 소유권을 주장해야 합니다. reference count를 책임질 필요가 있죠.
- 쓰면서 생각하다 보니 요즘 GC들은 죄다 Mark and sweep 방식이라, 굳이 소유권 신경 안 써도 알아서 사용중인 메모리로 잡혀서 안 지워지겠네요 -_-ㅋ...
그리고 한가지 더 짚고 넘어가야 할 것이, 최근의 배열들은 length 길이만 가지는 것이 아니고 최대 용량(capacity)를 동시에 가지고 있습니다. 비록 겉으로는 length 만큼 메모리를 할당하지만 내부적으로는 그보다 더 많은 메모리를 미리 할당해놓는 경우를 위해서인데요, 미리 충분한 양의 메모리를 확보해두면 배열에 값을 추가할 때마다 새 배열을 위해 메모리를 할당하고 값을 복사할 필요가 없어 훨씬 수행속도가 빠르기 때문입니다.
이를 위해서, slice에 ptr, len, capacity 3가지 정보를 필요로 하게 됩니다.
예를 들면, 일반 문자열(배열)의 경우

이런 식으로 문자열의 첫번째 포인터를 가리키게 되고
str[2:4] 같은 경우
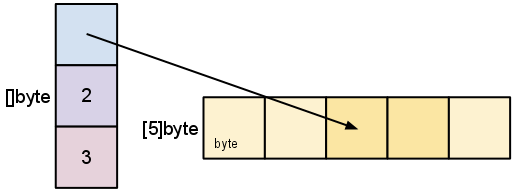
이런 식으로 slice 객체의 내부 상태가 정해집니다.
그런데 slice로 참조한 상태에서 원본 값이 변경될 수도 있습니다. 예를 들면:
str1 := "abcdefg"
str2 := str1[1:3]
str1 := str1 + "hijk"처럼 원본 문자열이 변경되고 새롭게 메모리가 할당되어야 하는 경우, slice는 자연스럽게 복사가 됩니다. slice가 변경되어야 하는 경우도 마찬가지입니다.
즉, 가능하면 shallow copy 하지만 필요하다면 통째로 복사를 수행하도록 합니다. 개발자가 의식하지도 못한 채 말이죠.
GC가 아닌 경우: Rust에서는?
Rust에서는 그 유명한 “대여" 라는 것이 있습니다. 어떤 객체를 참조하게 되면 원본이 되는 객체를 “빌렸다"라고 표현하는 것이죠. 그런데 Rust는 대여를 하게 되면 대여한 변수/함수가 끝나기 전까지는 대여 상태가 유지가 됩니다 (무려 그걸 컴파일 시간에 확인!). 누군가 빌려갔으면, 건드릴 수 없겠죠?
그럼 Rust에서, slice로 가져간 원본 문자열을 수정하는 상황을 다시 보겠습니다.
fn main() {
let mut s1 = String::from("hello");
let s2 = &s1[2..4]
s1.clear(); // error!!
}네, s2가 s1을 빌려간 상태이므로 s1은 더 이상 건드릴 수가 없습니다.
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5이런 식으로 고쳐쓰면 빌려감 상태가 끝이 나기 때문에 문제가 없겠죠.
fn main() {
let mut s1 = String::from("hello");
{
let s2 = &s1[2..4]
}
s1.clear(); // error!!
}그러니까, 런타임 단에서 편의를 제공하지 못한다면 아예 잘못된 코드를 쓰지 못하도록 막아주는 것도 하나의 안전함을 보장하는 방법이 되는 것입니다. 그렇지 못한 언어들은 “Use at your own risk” 하에서 사용하는 수밖에는 없겠죠.
이러한 구조적인 보장까지 되어야만이 slice의 shallow copy를 통한 성능과 안전성 측면을 모두 완벽하게 누릴 수 있는 조건이라는 생각을 합니다.
Multi-byte encoding에 대한 접근
조금 더 나아가서, 멀티바이트 인코딩에 대해서는 어떻게 접근하고 있는지 알아보았습니다.
멀티바이트 인코딩(가변 너비 인코딩)은 아시다시피 ANSI와는 다르게 한국어와 같은 복잡한 언어들을 여러 byte로 나타내기 위한 수단입니다. 나타내는 방식도 UTF-8, CP949, UTF16 등 여러가지가 있고요. 가장 중요한 특징은, 멀티바이트 인코딩은 아무데나 자르면 문자열이 깨져버린다는 것입니다 (= 의미가 없는 값이 돼요).
... C/C++과 같은 저수준 언어에서는 물론, 이 부분에 대해서 아무 보장을 해주지 않습니다. 어떻게 잘라서 쓰든 엿장수 맘이에요. 깨진 문자열도 의도한 것이겠거니 하고 자유를 존중해 줍니다. iconv와 같은 API를 써가면서 올바른 문자열 단위로 자를 수 있도록 노력해야만 합니다.
Go에서도 상황은 비슷합니다. 비록 내부에서 패키지로 도구를 제공해주긴 하지만, 결국은 멀티바이트 인코딩 된 문자열을 제대로 다뤄야 한다면 직접 문자열을 처음부터 읽어가며 byte 단위로 파악해야만 하죠. “잘못 쓰든 어쩌든 니 잘못” 이라는 스탠스입니다.
b := []byte(str)
idx := 0
for i := 0; i < 20; i++ {
_, size := utf8.DecodeRune(b[idx:])
idx += size
}반면 Rust는 이러한 부분에 대해서 일찍이 문제점을 인지하고 있었고, 그래서 재미있는 관점을 제시합니다. String을 접근하는 행위를 세 가지 관점에서 바라보았는데, 바로 바이트, 스칼라 값, 그리고 문자소 클러스터 입니다.
물론, 슬라이스를 얻는 행위는 바이트 단위로 이루어지는데, 그렇게 하기로 스펙으로 정해놨기 때문입니다. 또 일반적인 배열의 경우 이는 O(1) 에 이루어져야 하는 것이 스펙이기 때문이죠. 다만 Rust에서 문자열은 다릅니다! 문자열은 슬라이스(바이트) 접근할 때 유효한 문자열인지 확인을 하고, 따라서 인덱싱 비용이 O(1)이 아닙니다.
let hello = "Здравствуйте";
let s = &hello[0..1];
...
thread 'main' panicked at 'index 0 and/or 1 in `Здравствуйте` do not lie on
character boundary', ../src/libcore/str/mod.rs:1694이런 식으로 검사를 한 단 말이죠.
이를 위해서 앞선 방식들처럼 문자열이 차지하는 바이트 수를 찾아가며 Iterate 할 수도 있지만, rust에서는 좋은 방법을 제공합니다. chars() 쓰면 쉽습니다.
for c in "가나다".chars() {
println!("{}", c)
}물론, O(1)인 byte로 다루는 것 또한 가능합니다. bytes() 로 타입 캐스팅만 해주면 됩니다.
for b in "가나다".chars() {
println!("{}", b)
}아마 이렇게 문자열을 별도의 타입으로 보고, 유효성까지 검증해가며 접근할 수 있도록 언어 자체에서 내부적으로 지원한 경우는 Rust가 처음일 것입니다. 멀티바이트 인코딩도 실수로 사용하기 쉽고, 그럴 경우에 값이 완전히 깨지는 특징을 가지고 있어 굉장히 까다로운 특징을 가지고 있는데, 이를 언어 차원에서 막아준다는 것이 너무 마음에 듭니다. Go도 이런거 좀 해 줘라 ㅎㅎ...
참고
'개발 > Engineering' 카테고리의 다른 글
| DynamoDB와 Spanner, 어떻게 다를까? (0) | 2022.05.04 |
|---|---|
| 왜 ElasticSearch 인가? (0) | 2022.04.30 |
| Go의 메모리 과다 사용 문제 해결해보기 (0) | 2022.04.26 |
| Nginx가 고가용성을 유지하는 방법? (0) | 2022.04.25 |
| Django는 과연 무거운가? (0) | 2022.04.23 |