사실 같은 주제로 이전에도 썼던 글이긴 한데, 기존에는 다양한 프레임들만 짚고 넘어갔었던지라 그 깊이나 당위성이 좀 부족했다는 생각을 했었습니다. 여러 플랫폼들을 써 본 이제는 실제 사용하는 관점에서, 세부 요소들에 대해서 쓰고, 그리고 어떤 식으로 도움이 되는지에 대해 정리한 글을 써 보려고 합니다.
분산 시스템에서 Workflow 정의하고 사용하기
분산 시스템이 대세가 되고 이를 쉽게 구성할 수 있는 각종 프레임워크 및 플랫폼(K8s, EKS 등)이 도래하면서 시스템의 복잡도는 기하급수적으로 증가하고 있습니다. 프론트엔드, 백엔드 나누는 것은 기본이요, 요즘은 웹 서비스가 기본적으로 여러 어플리케이션 레이어, DB 등 수가지 서비스를 거쳐 진행되는 작업을 흔히 볼 수 있습니다.
이러한 작업을 어떤 식으로 관리할 수 있을지, 그리고 문제 발생 시 어떤 식으로 추적할 수 있을까요? 이를 위해 workflow과 분산 추적 시스템이 생겼습니다. 그 중에서 먼저 작업 관리 역할을 수행해주는 workflow에 대해서 다뤄 보려고 합니다.
Workflow 툴은 단순 하나의 마이크로서비스가 아니라 여러 마이크로서비스가 협력해서 순차적으로 진행되어야 하는 특정 작업들을 중개해주는 역할을 하는 서비스라고 볼 수 있습니다. 해당 툴 관련해서는 Apache Airflow가 대세이고, 최근 temporal 과 같은 툴들이 또 부상하고 있습니다.
워크플로우가 없다면?
먼저 워크플로우가 없을 경우부터 가정해 봅시다. 워크플로우가 없는데 여러 서비스들을 거쳐가야 하는데 복잡하고 오래 걸리는(약 30분) 작업을 수행해야 할 경우, 어떻게 할 수 있을까요?
먼저 워크플로우에 해당하는 작업을 정의해야 할 것입니다. 각 서비스는 작업 요청이 들어오면 파라미터를 받아서 결과를 만든 후, 이를 다음 파이프라인에 넘겨주어야 할 것입니다. 이를 위해 파이프라인에 해당되는 주고받을 객체를 정의하고, 또 이를 처리할 runner을 정의해야 할 것입니다.
이것들을 모두 정의하고 개발하더라도 여전히 고려해야 할 요소들이 있습니다.
- gRPC나 REST API를 이용하여 서비스간 정보를 주고 받는다?
- 이 경우 서비스가 예기치 못하게 종료되면 정보가 유실될 수 있습니다.
- Kafka, SQS와 같은 MQ 등을 이용하여 서비스간 정보를 주고 받는다
- 적어도 정보가 유실되지는 않지만...
- 각 서비스마다 queue / topic을 일일이 만들어 주어야 하고,
- 오퍼레이터 / 워크플로우를 수동으로 실행하고 싶으면 직접 데이터를 만들어서 큐에 넣어줘야 하는 고충이 있습니다.
- 테스크가 성공적으로 완료되었는지의 여부를 알 수 있어야 함
- 테스크를 기록하거나 관리할 주체, 혹은 저장소가 필요합니다.
위 사항에 해당되는 작업을 워크플로우 프레임워크에서 모두 처리해 주니 편리하게 사용이 가능합니다.
그렇다면 실제로 작업을 어떤 식으로 생성하고 관리할 수 있을까요? Airflow를 예로 들어 확인해 보면…
- 여기서는 Airflow의 구체적인 사용 예시 등을 다루지는 않습니다
워크플로우의 정의
먼저 워크플로우의 구성요소부터 정리해 보면, DAG와 오퍼레이터가 있습니다. 그리고 각각의 세부적인 활용 예를 정리해 두었습니다.
1. DAG
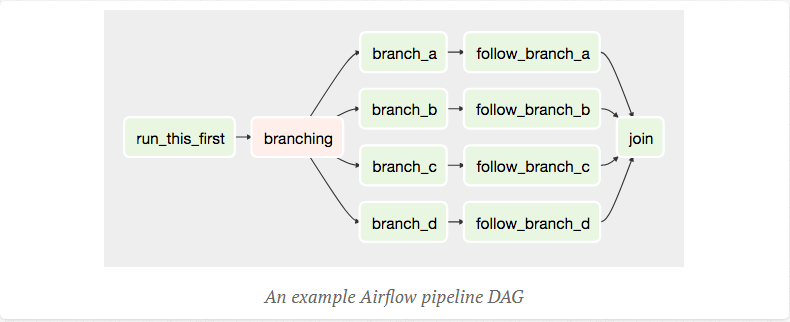
DAG 생성시 간단한 검증 작업이 수행됩니다.
- 워크플로우는 작업들로 구성된 DAG가 될 것을 원칙으로 합니다. 작업이 무한히 진행되는 것을 막기 위한 기본 원칙입니다.
- 워크플로우에 다양한 정보를 줄 수 있습니다. 자동 주기적 실행을 위한 interval(for Batch Process), 시작시점 정도…
- 생성된 워크플로우 데이터는 내부 DB에 저장됩니다.
아래와 같은 python script로 DAG 생성을 할 수 있는데,
dag = DAG('hello_world', description='Simple tutorial DAG',
schedule_interval='0 12 * * *',
start_date=datetime(2017, 3, 20), catchup=False)
dummy_operator = DummyOperator(task_id='dummy_task', retries=3, dag=dag)
hello_operator = PythonOperator(task_id='hello_task', python_callable=print_hello, dag=dag)
dummy_operator >> hello_operator생성하고 나면 UI 상에서 아래와 같이 Workflow를 확인할 수 있습니다.
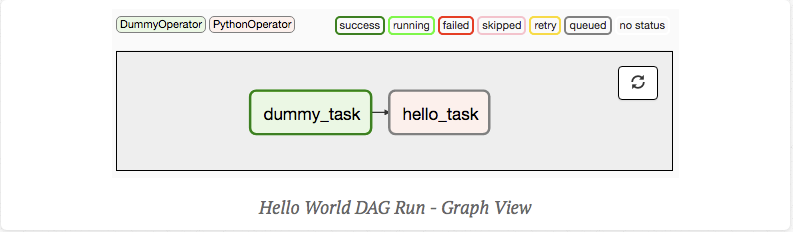
2. 오퍼레이터
이러한 DAG를 구성하는 세부 단위를 보면 오퍼레이터를 확인할 수 있습니다.
- Operator(= Task step)에서는 실행에 필요한 로직과 세부 정책들을 정보를 담고 있습니다. (최대 재시도 횟수, 최대 실행시간 등 …)
- Sensor이라는 실행 제어를 위한 특수한 오퍼레이터 객체가 존재합니다.
- 이를 이용하여 상호 Workflow간 관련성/상태를 접근할 수도 있고,
- 굳이 workflow로 한정짓지 않고, 특정 조건이 될 때까지 기다리게 만들 수도 있습니다. 예제
- 오퍼레이터간 메시지를 전달하는 방법은 xcom이라는 객체를 이용하여 데이터를 전달합니다. 오퍼레이터를 일종의 함수라고 볼 수 있으니, 이전 함수가 다음 함수에 필요한 인자를 던져주는 기능은 당연히 있어야겠죠?
- 다만 이 방식은 제약이 커서, 큰 메시지의 경우 등은 외부 저장소를 사용해야 할 수 있습니다.
def example_xcom_push(ds, **kwargs):
kwargs['ti'].xcom_push(
key="example_xcom",value=str(1))
def example_xcom_pull(ds, **kwargs):
pull_value = kwargs['ti'].xcom_pull(
task_ids='', key='example_xcom')
print(pull_value)
push_task = PythonOperator(
task_id='example_xcom_push_task',
python_callable= example_xcom_push,
dag=dag,
)
pull_task = PythonOperator(
task_id='example_xcom_pull_task',
python_callable= example_xcom_pull,
dag=dag,
)출처: https://yogae.tistory.com/32
어쨌든 정리하면, DAG와 이를 구성하는 오퍼레이터가 합쳐져서 하나의 워크플로우를 실행하게 되는 개념입니다.
워크플로우 실행 및 관리
Airflow가 워크플로우 관리 프레임워크인만큼, 태스크를 실행하기 위한 방법도 제공하고 있습니다.
- 자동으로 스케줄러를 이용하여 돌리거나,
- airflow에 직접 request를 전송하여 작업을 실행하거나
- 혹은 shell에서 수동으로 직접 실행시킬수도 있습니다.
airflow dags trigger {dag_id} -c 'params'다양한 방식으로 워크플로우를 실행할 수단을 프레임워크 자체에서 제공해주고 있어, 복잡한 워크플로우를 개발하고 테스트하는데 있어서 굉장히 편리한 장점으로 작용합니다.
현재 워크플로우 툴들의 특성
이러한 워크플로우 툴들의 장점이라고 생각되는 점들에 대해 끄적끄적 적어봅니다.
- Workflow 자체가 별도 시스템으로 만들어져 있어, 다른 서비스와 의존성이 낮습니다.
- API 같은 것들을 사용하여 구현할 필요가 없기 때문에** 서비스가 workflow에 의존성을 띄지 않고, 이벤트 기반으로 워크플로우를 자연스럽게 구성할 수 있게 됩니다. *예를 들어 워크플로우가 작업을 수행해달라고 요청하면, 각 서비스가 작업 수행 후 결과를 통보해주는 방식으로 개발을 할 수 있는 것이죠.
- 워크플로우의 생성/관리/신뢰성에 대해서 걱정할 필요가 없습니다.
- 만약 워크플로우 플랫폼을 직접 만든다고 가정하면, 기본적인 테스크 생성, 실행 로직 이외에도, 테스크 실행 도중 중단되는 상황을 고려해서 각 오퍼레이터 사이에 메시지 큐 같은 persistent 요소를 구성해야 할 것입니다. 그러한 고민을 할 필요가 없으니 굉장히 큰 장점입니다.
- 이와 더불어서 Batch Processing과 같은 경우 crontab을 만들어 돌려야 했을 것이고, 과거 이력도 찾아보기 어려웠을 것입니다.
- 또한, Workflow 생성시 발생하는 여러 문제(잘못된 DAG, 자동 재시도 등)를 예방해주거나 쉽게 해결하게 해 줍니다.
- 워크플로우의 사용이 몹시 편합니다. 명령어, 스케쥴러, 외부 호출 API 등 다양한 방식을 지원하고 있어 쉽게 사용이 가능합니다.
재미있는 점은, 스케쥴러 기능이 내장되어 있는 덕분에 Workflow는 실시간 서비스 파이프라인으로도 많이 쓰이지만, jenkins과 같은 배치/단발성 작업에서도 많이 쓰이는 것 같습니다.
이렇게 workflow 툴이 많은 것들을 도와주지만, 막상 우리가 짜놓은 로직에 문제가 발생하면 확인해야 하는 요소가 많은 분산 시스템 특성상 원인을 찾기가 무척 어려워집니다. 이를 위해 분산 추적 시스템이 존재합니다.
Distributed tracing의 필요성
Distributed tracing 툴은 분산 시스템에서의 워크플로우 단위의 기록 추적을 도와주는 툴입니다. 분산시스템의 경우 로그 또한 각 시스템별로 분산되어서 저장되게 되는데, 이를 “Task”와 같은 의미 있는 단위로 묶어 로그 및 실행 내역 확인을 할 수 있도록 도와주는 역할을 해 줍니다. Relic, Zipkin 등이 있겠네요.
없으면 어떨까요?
예를 들어 10단계로 구성된 워크플로우가 있는데 중간에 실패한 기록이 발생해서, 해당 어플리케이션에서 발생한 로그를 확인해봐야 한다고 가정해 봅시다.
- 일단 실패한 어플리케이션 명을 찾아내어, 해당 시간대의 로그를 로그 저장소로부터 가져옵니다.
- 그런데 로그를 찾아보니 이전 태스크에서 만든 데이터가 잘못된 것 같습니다.
- 그래서 이전 테스크의 로그를 확인하기 위해서, 다시 워크플로우 DAG 확인 후에, 문제가 발생한 어플리케이션과 시간대를 다시 찾아 로그 저장소를 또 찾아갑니다.
- 이번엔 해당 테스크에 들어간 데이터가 잘못되었기 때문에, 또 이를 생성한 DAG를 찾고, 연관된 로그를 뒤지고…

어후, 생각만 해도 더부룩합니다. 그나마 이건 오류가 발생한 상황이라서 추적하기가 용이한데, 과부하 등으로 테스크 타임아웃 발생, 응답없음 등의 상황에서 로그를 뒤져야 할 일이 생긴다면 정말 찾기가 힘듭니다.
분산 추적 툴은 이러한 일련의 과정을 쉽게 추적할 수 있게 해 줍니다. 만약 분산 추적 툴이 있었다면,
- 연관된 테스크들을 쉽게 그래프 형태로 확인할 수 있을 뿐만 아니라,
- 각 테스크의 세부 스텝(오퍼레이터)의 세부정보를 알 수 있고 (오류여부, 수행시간, 로그 등)
- 필요하다면 연관된 다른 태스크(부모 및 자식 테스크)를 찾아 추적할 수 있고
- 이를 통해 다른 서비스 및 로그를 추적할 필요 없이 오로지 분산 추적 툴만으로 디버깅 가능
하다는 굉장히 강력한 이점이 있습니다. 또한, 숙련된 CS/QE의 경우 해당 툴만으로도 대처가 가능하거나, 혹은 개략적인 문제 상황을 빠르게 전달하여 빠른 진행을 할 수 있다는 장점 또한 있습니다.
분산 추적에 필요한 요소
그렇다면 이러한 기능 구현에 필요한 요소들은 어떤 것들이 있을까요? OpenTracing에서는 분산 추적에 있어 아래 요소들을 공통적으로 필요 요소로 규정하고 있습니다.
- 테스크 ID
- 일련의 연속된 작업(= 테스크)을 규정하기 위한 이름
- 중복되지 않도록 할 필요가 있으나, 보통 time range를 두어 연관된 태스크를 ID를 묶으므로 그렇게까지 신경 쓸 요소는 아닐 것입니다.
- 스텝 ID
- 오퍼레이터에 해당되는 개념으로, 실제 수행되는
추가로 아래 요소들을 더 넣을 수 있을 것입니다.
- Task 및 Step이 전달받은 값과 다음 테스크로 전달하는 값
- 해당 Step에서 발생한 로그, 오류 및 콜스택
- 수행 시간
- 연관되는 테스크 ID 정보
- 상수 테이블 — callstack 등 문제를 빠르게 추적할 수 있는 간단한 정보들을 담고 있음
- 등등
이를 기반으로, 각 테스크에 대해 로그를 취합하여 아래와 같이 시각화 할 수 있을 것입니다.
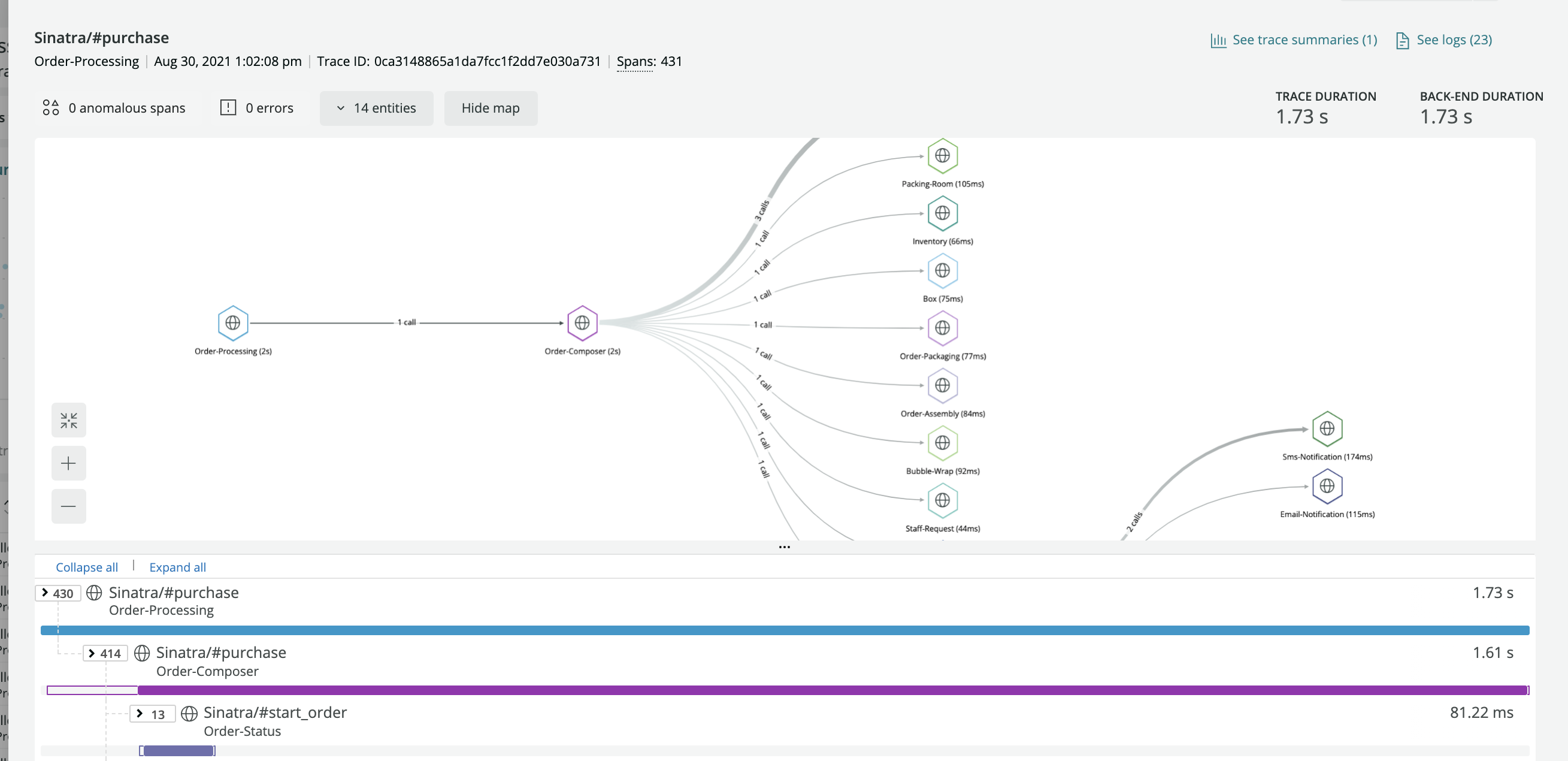
출처: https://docs.newrelic.com/kr/docs/distributed-tracing/ui-data/understand-use-distributed-tracing-ui/
분산 추적 툴 중 하나인 Relic인데, 테스크 내역을 한 눈에도 보기에도 편리하고, 무엇보다 분산 시스템에서 만들어진 로그를 취합해서 만들어진 것이라고 믿기 힘들 정도로 테스크 기준으로 작업 요소들이 잘 정리되어 있는 모습을 볼 수 있습니다.
분산 추적 로깅에 대해서
그렇다면 모아야 할 정보들을 알았다면, 어떻게 정보를 모을 수 있을까요? 주로 두 가지 접근 방법을 씁니다.
1. API를 통한 방식
임의로 API를 통해 테스크 및 오퍼레이션을 정의하는 방식입니다.
여기에서도 수동적 방식, 자동적 방식으로 방식이 나뉩니다.
- 수동적 방식: 코드에 임의로 작업 시작시에 테스크 및 오퍼레이션을 정의하도록 해야 합니다.
- 워크플로우에 맞도록 코드를 전부 수정해야 하는 부담이 있을 수 있습니다.
- 자동적 방식: 빌드 파이프라인에 자동으로 코드/바이너리를 추가해주도록 해서 API를 자동으로 삽입하는 구조입니다.
- 구조가 다소 복잡하여 디버깅이나 기능 추가에 어려움을 겪을 수 있을지도..?
- 네이버에서 이 방식을 쓴 적이 있다고 합니다.
코드에서 테스크를 정의하고 전달하는 만큼 편리한 편이긴 한데, 어떤 방식이든 API가 코드에 직접 삽입되는 구조이기 때문에, 의존성이 다소 크고, API가 크게 달라질 경우 서비스를 모조리 재시작해야 할 수도 있다는 단점이 있습니다.
2. 로그를 통한 방식
Event-driven 아키텍쳐처럼, 어플리케이션에서 발생하는 로그를 기반으로 테스크를 추적하는 방식입니다. 이러한 포멧에 대한 규격 또한 이미 존재하는데, 대표적인 것이 OpenTracing 입니다. ****자세한 specification은 이 링크에서 설명되고 있습니다. 간단하게 정리하면…
Each Span encapsulates the following state:
- An operation name
- Start ~ End timestamp of the Span
- Span Tags
- Span Logs
- SpanContext (= state or kind of task id for process boundary)
- Reference (to other spans, if necessary)
- (여기서의 span = task 입니다)*
굳이 specification을 따르지 않을지라도, 기본적으로 분산 추적에 필요한 요소들에 대해서 정의해두고 있다는 점에서 참고할 만한 좋은 기준이 됩니다.
해당 방식의 분산 추적을 지원하는 툴로는 Jaeger, Zipkin(deprecated 됐다는 이야기가 있습니다) 등이 있습니다. 사실 근래 나오는 대부분의 툴들은 위 방식들 다 지원합니다
저희 회사에서도 Workflow에 API를 붙이는 방식으로 분산 추적을 할 수 있는 툴을 만들어서 사용하고 있습니다. 배치 작업보다는 실시간으로 데이터를 처리하는 구조에 맞는 분산 추적 툴이 필요하였기에, 기존의 툴을 사용하는 대신 AWS SQS로 파이프라인을 구축하여 워크플로우 로깅과 트레이싱을 동시에 할 수 있도록 정보를 남기는 독자적인 프레임워크를 만들고, 이를 시각화하여 확인할 수 있는 웹 서비스를 만들어서 사내에서 사용중에 있습니다.

이처럼 디버깅 툴 안에서 워크플로우 작동 상황과 동시에 결과값, 수행시간 등 필요한 정보를 모두 조회할 수 있습니다.
확실히 해당 툴을 이용하면 문제 발생 시 직접 각 서비스의 pod를 조사하거나 / CloudWatch까지 들어가 로그를 일일이 확인해 볼 필요 없이, 분산 추적 툴에서 진행상황 확인과 동시에 세부 로그까지 동시에 볼 수 있어 정말 편리합니다.
이처럼 복잡한 파이프라인이 필요한 구조에서는 워크플로우와 분산추적 툴은 같이 구성이 되어 있어야만 시스템 유지가 훨씬 쉽습니다.
물론 해당 툴은 앞으로도 개선할 점이 많아서 (의존성 줄이기, UX 개선, 편의기능 추가 등), 다른 툴들을 벤치마킹하거나, 자체 프레임워크에서 발생하는 문제를 고쳐나가고 있습니다. 그리고 해당 툴은 이후에 기회가 된다면 오픈소스화 할 계획도 있습니다. 혹시 해당 분야에 관심이 있으시다면, 같이 일하면서 개선해 보지 않으실래요? 🙂
'개발 > Engineering' 카테고리의 다른 글
| 대용량 로드밸런서 설계 (0) | 2022.07.24 |
|---|---|
| Storage as a DW (Data Warehouse) (0) | 2022.07.04 |
| MongoDB로 효율적인 자료구조 설계 하기 (0) | 2022.06.30 |
| 한 서버가 어떻게 16K 이상의 연결을 맺을 수 있을까? (0) | 2022.05.30 |
| MSA에서의 디자인 패턴 (0) | 2022.05.28 |