Merge sorted K lists
이 문제도 면접 보면서 꽤나 자주 본 단골 문제인데, 뭔가 문제가 착각하기 쉬운(?) 점이 있어 정리할 겸 적어둔다. 역시 단골문제답게 GeeksforGeeks에도 있다.
설명을 잘 하려고 쓴 글이 아니라서, 오히려 이 글을 읽으면 더 헷갈릴 수 있습니다. 그냥 g4g를 보세용 😅
문제는 아래와 같다. 정말 간단하다! (GeeksforGeeks에서 그대로 긁어왔습니다)
Input: k = 3, n = 4
list1 = 1->3->5->7->NULL
list2 = 2->4->6->8->NULL
list3 = 0->9->10->11->NULL
Output: 0->1->2->3->4->5->6->7->8->9->10->11
Merged lists in a sorted order
where every element is greater
than the previous element.
Input: k = 3, n = 3
list1 = 1->3->7->NULL
list2 = 2->4->8->NULL
list3 = 9->10->11->NULL
Output: 1->2->3->4->7->8->9->10->11
Merged lists in a sorted order
where every element is greater
than the previous element.그러니까, n개의 값을 가지고 있는 K개의 정렬된 리스트를 MergeSort 하는 것이 핵심이다. 설명의 편의를 위해, 전체 number 개수를 N 이라고 가정한다.
여기서 놓치면 안 되는 핵심이 또 있는데, 바로 Sorted 이다.
일반적으로는 각 리스트마다 인덱스를 만들게 되는데, 즉 “인덱스 배열"을 만들어서 문제 접근을 하게 된다. 나름 합리적인것 같긴 하다. 이러면 시간복잡도는 O(KN) 이 나오게 된다. 왜 N 이냐면, 값 하나를 뽑아낼때마다 K 리스트의 값들을 모두 비교해서 가장 작은 값을 가지고 와야 하기 때문이다.
그런데, 잘 생각해보면 뭔가 이상하다는 점을 알 수 있다. 일단 설명은 조금 뒤에 …
또 다른 간단한 방법은, 배열들을 모조리 하나로 합친 후 Sort 하는 것이다. 이 경우 크기 N 의 배열을 만들고 이를 sorting 하기 때문에, O(N log N) 이기 때문이다.
앗, 그런데 이거 K 가 커지면 첫번째 방식의 경우는 시간복잡도가 이것보다도 떨어지게 된다!! 그래서 첫번째 알고리즘은 좋지 못한 답변이 된다. 시간복잡도를 정확히 파악할 수 있는 능력을 보는 건데, 난 유독 저 부분 시간복잡도가 잘 안 와 닿는다 😅
괜찮은 답변은 분할정복 MergeSort이다. 그러니까, 2개씩 머지하는 것이다. 그냥 머지소트랑 완전히 똑같음.
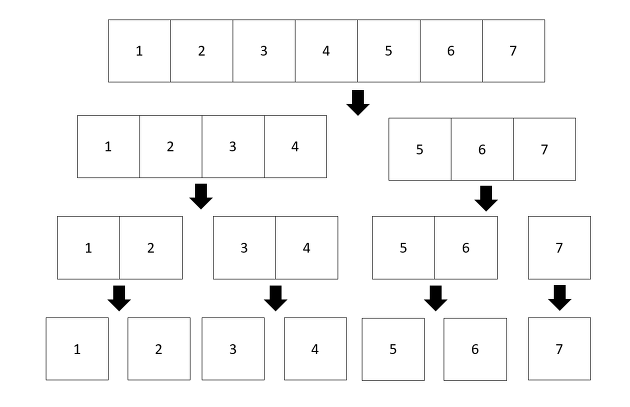
머지하는 시간복잡도 자체는 최악일지라도 O(N) 이고 (가장 마지막 머지하는 케이스), K개의 분할이므로 머지 횟수는 log(k) 임이 자명하다. 따라서 전체 시간복잡도는 O(N logk) 이다. 의외로 “인덱스 배열"을 사용하는 첫번째 방식에 비해 훨씬 Optimized 된다. 🤔 난 이 부분이 의외로 직관적이지 않게 느껴졌음.
가장 깔끔한(?) 답변은 heap(K size)을 쓰는건데, 무슨 소리냐면 각 리스트에서 가장 작은 값들로 구성된 heap을 만드는 것이다. 이게 가능한 이유는 우리는 리스트 중에서 가장 작은 값만 가지고 오면 되기 때문이다. 즉 모든 K 리스트의 최소값을 비교할 필요가 없는 것이다. heap pop을 수행하면서, pop한 node의 next node를 heap에 밀어넣어주는 식으로 만들면 어렵지 않게 구현할 수 있다.
- 실제 대회를 할 때는 보통 heap 구현하는 코드를 짜지는 않고, STL의 priority queue 를 써서 많이들 해결한다. 뭐, 그래도 구현도 쉽고 vector로 heap 구현하는 건 한번 쯤 짜보는 건 분명히 도움이 된다.

머지소트 방식도 직관적이지 않다고 했지만 사실 어떻게 보면 또 말이 되는게, 마찬가지로 모든 K 리스트의 최소값과 비교하는 작업을 하지는 않는다.
머지소트를 통해 값을 뽑아오는 과정은 일련의 토너먼트와 유사한 점이 있다. 가장 작은 값을 리스트 두개끼리 붙여서 고르고, 거기에서 가져온 작은 값 끼리 또 비교하고… 이러면 모든 pairwise 비교를 할 필요가 없어지니 logk 번 비교만 해도 되는게 납득이 된다!
'개발 > Algorithm' 카테고리의 다른 글
| Two-Sum 문제 (0) | 2022.07.28 |
|---|---|
| MST 문제, 그리고 우선순위 큐 (0) | 2022.07.27 |
| 2개씩 나오는 숫자들 중 하나만 나오는 숫자 찾는 문제 + ⍺ (0) | 2022.07.26 |
| Persistent Data Structure (0) | 2022.02.28 |
| 알고리즘 관련 학습 사항 정리 (0) | 2017.04.27 |