
컨테이너 기반 가상화 기술인 Docker가 13년경 출시된 이후로 많은 서비스들이 이를 이용하여 운용되기 시작했습니다. 자원 분배, 환경 분리, 기존 VM 기술 대비 극한의 가벼움을 가지고 있어 수요에 크게 부합했기 때문입니다. 하지만 이러한 기술들 중 가장 널리 알려진 Docker과 이것이 사용하는 containerd 기술은 사실 컨테이너 가상화 기술 중 일부이고, 지금도 계속해서 새로운 기술들이 만들어지고 있습니다. 구체적으로 어떤 점에서 개선이 이루어졌는지 알 필요가 있을 것 같아서 공부를 좀 해 봤습니다.
도커의 구조, 그리고 다양한 표준
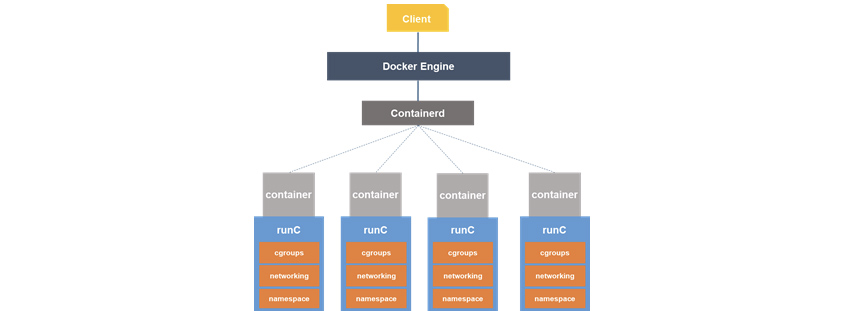
도커 엔진 Dockerd와 Containerd에서부터 컨테이너를 실행하라는 명령이 내려지면, 실제로 컨테이너 프로세스를 구동하는 것은 runC의 몫입니다. 이는 리눅스 커널단에서 지원하는 cgroup와 namespace 기능을 이용하여 이루어집니다.
여기에서 Docker과 Containerd는 고수준 컨테이너 런타임(컨테이너에 적합한 형태의 인터페이스를 CRI라고 일컫음)*에 해당되고 runC는 저수준 컨테이너 런타임에 해당된다고 하네요 *(커널 API에 직접 접근한다고.. 이를 OCI 표준이라고 한다고 합니다)
다양한 OCI, CRI의 도래
시간이 지나면서, 도커가 사용하는 containerd를 대체하기 위한 여러 CRI 들이 만들어지기 시작했습니다. 이를테면 현재 유행하는 쿠버네티스 같은 경우 CRI-O와 같이 ORI 인터페이스를 준수하는 고수준 컨테이너 런타임을 별도로 개발하여 쓰게 되었습니다. 이에 따라 이미지 생성을 위한 CRI도 새로 만들어 쓰게 되었습니다.
그런데 왜 굳이 있는 것을 안 사용하고 새로 만드려고 했을까요? 그 이유는 도커의 아키텍쳐가 가져다주는 문제점에 있습니다.
첫번째로는 SPOF(단일 실패점)의 위험성입니다. 도커의 구조를 보면 runC 들이 containerd CRI 밑에 자식 프로세스로 두고 있는 모습인데, 그 말은 docker container daemon이 죽으면 얄짤없이 모든 프로세스가 죽어 버립니다. 두 번째로는 무거움입니다. 해당 데몬은 이미지 생성 관리 등의 역할도 하고 있어, 서비스만을 위해 사용하기에는 무겁기까지 합니다. 따라서, 이것들을 분리할 필요성이 생기게 됩니다.
이를 해결하기 위해 Podman과 같은 새로운 컨테이너 가상화 프로그램 같은 것들이 나오게 됩니다. 이미지 생성과 같은 별도의 기능은 툴로서 분리하고, 기존 도커가 클라이언트-서버 구조를 이용했던 부분을 fork-exec 구조로 바꾸어서 명령 수행에 루트 권한이 필요했던 문제, 그리고 컨테이너를 네임스페이스에서 직접 돌리도록 하여, 궁극적으로는 SPOF를 해결하였습니다.
KVM의 도래
그와중에 KVM(Kernel-based Virtual Machine) 기술이 등장하기 시작합니다. 2007년부터 리눅스 커널에 도입된 기술인데, 리눅스 자체를 하이퍼바이저로 가상화시켜 구동하는 기술입니다. 위의 컨테이너에서 사용된 OCI 기술과 가장 큰 차이점이라고 할 수 있습니다.

다만 여기에는 종류가 2가지가 있는데, TYPE 1의 경우 베어메탈로 하드웨어 바로 위에서 실행되는 구조입니다. 그림에서 보이는 것처럼 하이퍼바이저가 하드웨어를 관장하는 형태이기 때문에 사실상 호스트 운영체제를 설치할 때 같이 설치되어야 합니다.
주로 Hyper-V나 KVM이 이러한 TYPE 1 형태입니다. 둘 다 커널 내에 기능이 내장되어 있다는 공통점이 있네요. 그리고 Hyper-V 활성화 시 VT를 반드시 활성화해야 한다는 경고문이 왜 붙어있는지 이해가 이제 가네요... 🤔
TYPE 2 의 경우, 하이퍼바이저가 호스트 OS 위에서 실행됩니다. 정확히 VMWare, VirtualBox, QEMU와 같은 구조가 됩니다.
TYPE 1이 2에 비해 훨씬 가벼운 특징이 있는데, 커널단에서 하드웨어와 바로 접근하기 때문에 훨씬 하드웨어 부하가 적습니다.
그리고 이건 사실 베어메탈과 호스트의 차이는 아니긴 한데, 호스트 된 운영체제의 경우 커널부터 에뮬레이트하여 구동되는 경우가 많습니다. 이 두 특징이 겹쳐져서 타입1과 타입2의 용도 및 성능이 보통 큰 차이가 나는 형태가 됩니다.
아마존의 새로운 가상화 기술 Firecracker, 그리고 Lambda

여기까지 왔으면 이제 Firecracker에 대해서 설명을 할 수 있습니다. Firecracker는 amazon에서 개발한 가상화 기술로서, 기존 docker이 제공하는 가상화와는 다르게 TYPE 1 베어메탈기반의 가상화 컨테이너를 사용합니다. 이를 통해 고도의 보안(security)를 달성할 수 있지만, 대신 성능(오버헤드)과 호환성에 대해 트레이드오프가 필요합니다.
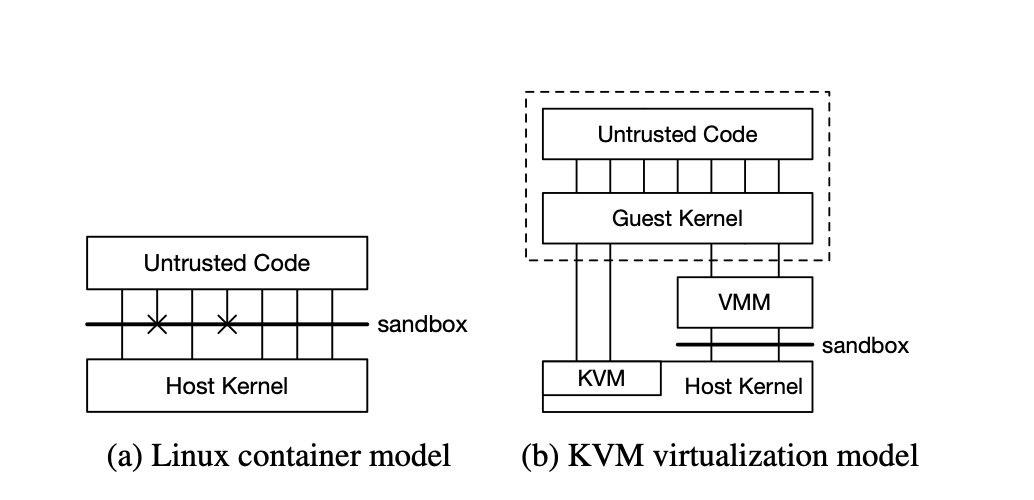
이런식으로 Guest Kernel 위에서 코드가 돌아가므로 보다 isolated 환경에서 돌아가게 됩니다.,
하지만 Firebase는 단 125ms만에 KVM 위에 microVM을 띄울 수 있다고 하니 괄목할 만한 성능입니다. microVM은 Kernel+VMM을 썼는데, 커널 자체는 Linux 커널이 이미 잘 하고 있어서 그렇게 건드리지 않았다고 합니다.
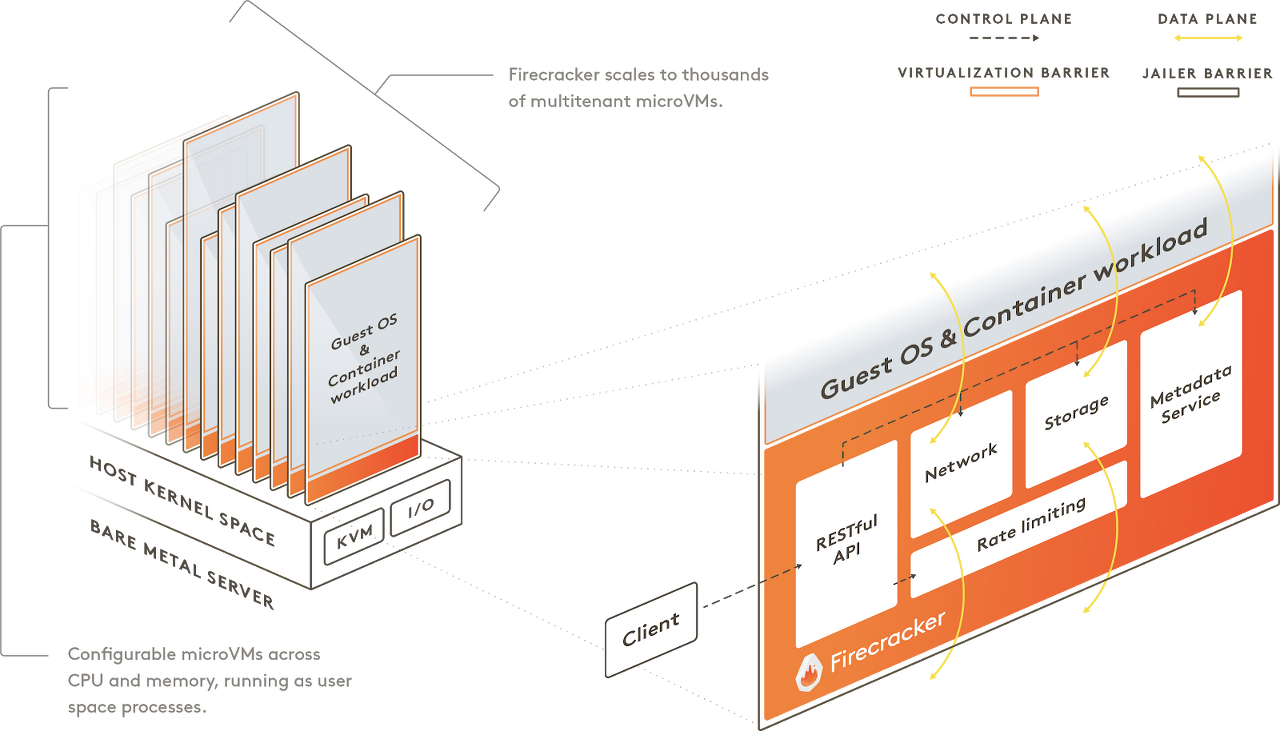
그렇다면 이 점에 있어 핵심 포인트는 VMM(Virtual machine monitor) 입니다. 위 그림에서 보이는 것처럼, microVM 위에 얹혀서 자원 관리 및 제한, 드라이버 (네트워크, 저장소) 등의 작업을 합니다. 일반적으로 많이 사용되는 QEMU 기반으로 개발되었으나, 최대한 경량화된 코드를 사용하였다고 합니다. (Rust 기반으로 불필요한 드라이버 같은 것들을 다 빼고 chrome OS VMM 기반으로 설계).
덕분에 microVM 부팅 시간 및 자원 소모량(오버헤드)를 크게 줄일 수 있었다고 합니다. 덕분에 이러한 설계와 구현에도 불구하고 실제 Firecracker로 인한 메모리 부하는 3% 정도에 불과하다고 하네요.

이와 같은 Firecracker의 고도의 분리성과 성능을 토대로 하여, AWS Lambda 및 Fargate 서비스가 구동이 되고 있다고 합니다. Lambda의 경우 micro manager이 일종의 docker과 같은 매니징 역할을 하고 실제 수행은 microVM 위의 게스트OS에서 구동되는 것을 확인할 수 있습니다.
추가로 Lambda 수행 시 아래 정도의 특이사항이 있습니다.
- 한 번 수행된 lambda는 재수행 시 동일 routing을 통해 high-availability와 성능을 보장(less payload)하도록 함. Worker Manager이 하는 중요한 일 중 하나
- Lambda는 “slot”과 1:1 대응되는 관계이고, slot이 부족할 경우 적절한 최적화를 통해 Worker Manager이 20ms 내로 slot를 확보한다고 함 (이건 구체적인 설명 없나...?)
- MicroVM 각각이 단일 “slot”를 제공하는 형태 (1:1 대응). 미리 Pre-booted되어있는 풀을 통해 빠른 startup을 제공함.
- slot는 3가지 상태를 가지고 있음: init, idle, busy. idle 슬롯의 자원을(CPU) busy/init 에 넘김으로서(Overscription) 리소스 효용을 최대화하고자 함. uncorrelated workload를 worker에 분배함으로서 contention(간섭) 없이 이를 극대화시켰다고 함.
- MicroVM은 Frontend와 소통하는 관계인데, 다소의 TCP/IP 오버헤드가 있으나 모니터링, 보안 측면에서의 이점을 챙길 수 있음
워낙 겉핥기로 정리한 거라 깊이는 한참 부족하지만 일단은 여기까지 😅
참고
- 논문(firecracker)
- 흔들리는 도커(Docker)의 위상 - OCI와 CRI 중심으로 재편되는 컨테이너 생태계
- Redhat의 KVM 문서
- https://velog.io/@ayoung0073/OS-Firecracker
- http://cloudrain21.com/hypervisor-types
- 비슷한 관점에서 잘 정리해주신 글입니다.
'개발 > Engineering' 카테고리의 다른 글
| kubernetes troubleshooting flowchart (0) | 2022.05.26 |
|---|---|
| Unique ID Generator의 설계 (0) | 2022.05.06 |
| Borg로 알아보는 클라우드 환경에서의 컨테이너 매니징 (0) | 2022.05.06 |
| AWS가 이야기하는 Well-Architected Framework (0) | 2022.05.06 |
| 리눅스 커널 바로 위에 executable 얹기 (0) | 2022.05.04 |