요즘 골머리를 앓는 문제가 있었다. S3를 데이터 저장소로 쓰는 게 가능할까? 왜냐하면 S3는 대표적인 싸고 무난하게 데이터 오래 보관하기 좋은 저장소이기 때문이다.
문제는 가끔가다 거기서 데이터를 꺼내 쓸 일이 있을 것이라는 거다. 즉 자주 쓰는 대부분의 데이터는 mongoDB 같은 데에다 넣고, 가끔 아주 낡은 데이터를 조회하는 리퀘스트 응답이나, 혹은 데이터 분석할 때 필요한 수준이기 때문에, 성능은 별로 필요가 없는 상황.
그런 요구사항이 가능한지 찾아봤는데, 의외로 방법이 있네? 싶어서, 조금 조사해서 정리해 놓았습니다.
요즘 계속 바쁘고 정신이 없어서 그냥 음슴체로 썼습니다.
왜 써야함?
아래 내용은 딱히 정론은 아니고, 적당히 내 사심을 담아서 당위성을 정리해 봄…
- 비용 절감
- 저렴하게 저장할 수 있음. 부동 원탑의 이유
- DB에 모든걸 다 담기엔 캐시 용량도 크고 (= 동일 기능 제공하려면 더 비쌈)
- 오래된 데이터 분리 (어차피 오래된 데이터는 액세스 안 할 것이 전제되므로)
데이터 전체 마이그레이션 할 경우에는 불필요한 비용 추가되는 것도 방지.
- 대규모 데이터 활용에 최적화
- 이를테면 머신러닝같은 분석 작업에 최적화된 저장소에 저장 가능
- 속도향상도 있음: 최적화된 데이터 구조, 실제 서비스하는 DB와 별개로 위치하여 부하 분리.
- 아키텍쳐 보면 알겠지만, 저장 방식 자체가 다르다. transaction X, 읽기 최적화
- 그 이외: 보안…?, 등…
아무래도 변경될 일이 없는 오래된 데이터 저장에 적합하다. 결국 내가 위에 썼던 저 찾고있던 용도에 부합하는 셈.
데이터 레이크(Data Lake)와는 어떻게 다른가

출처: https://loustler.io/data_eng/diff-data_lake-data_warehouse/
가장 큰 차이점은 아무래도 정규화 여부라고 볼 수 있을 것이다. 데이터 레이크는 정형화된 구조가 없거나 / RAW 데이터라서 사용하려면 변환되어야 하는 데이터이다.
그리고 … 이런 골치아픈 것을 좋아하는(?) AWS에서는 역시나 솔루션을 제공하고 있습니다.

뭔가 이것저것 많이 얽혀있는데, 결론만 놓고 정리하면 데이터 레이크에 저장된 비정규화된 데이터를 오른쪽(OpenSearch, CW, Glue⇒Athena로 DW화, S3 등) 방식을 이용해서 적절하게 만들어 쓰면 된다, 라는 이야기입니다…
이러한 작업을 하기에 유명한 인프라로는 AWS Glue가 있음.
- 물론 각종 서드파티 툴들이 비정규화 데이터에 대한 기본적인 분석을 해 주어서 이를 돕는 경우도 있습니다. (이미지 분석 자동 태깅, 텍스트 검색 등…)
즉, 데이터 레이크에 들어있는 비정형 데이터는 최소한의 포멧 파악/정규화가 필요한 상태라고 볼 수 있습니다. 수작업이 필요한 괴로운 데이터가 되겠습니다…
- 데이터 레이크가 비용 측면에서 더 싸다고 하는데, 저장 측면에서는 거의 차이가 없기 때문에 (On-premise 여부만 좀 다를지도..?) 소프트웨어를 이용하는 비용 빼고 보관 비용은 거의 차이가 없다고 볼 수 있을 것 같습니다. 오히려 활용 못하는 데이터 형태면 무슨 소용이 있나 싶은데…
- 다만 데이터 레이크가 데이터 웨어하우스로 가기 전 형태의 데이터인 만큼, 데이터 웨어하우스를 사용하더라도 중간 데이터 포멧으로서 다른 선택지가 없이 써야 하는 경우가 있을 수 있습니다.
DB와의 차이점은 무엇인가
데이터의 유연성
단순히 파일로 저장하는 것이 가능하다가 관건인가? No. 다양한 저장소, 포멧을 지원하는 것이 관건.
일례로: SQLite? 파일로 유연하게 저장은 가능하지만 여러 저장소를 통합해서 보는 것은 어렵.
데이터의 쓰기(업로드)
DB처럼 자유롭게 쓰기는 불가능. 스토리지에 저장을 위한 별도의 파이프라인을 구축해야 한다.
별도의 파이프라인을 구축하다 보면 자연스럽게 데이터 레이크가 필요할 수도 있음. (가공 전 파일을 저장해야 하는 용도)
예컨데,
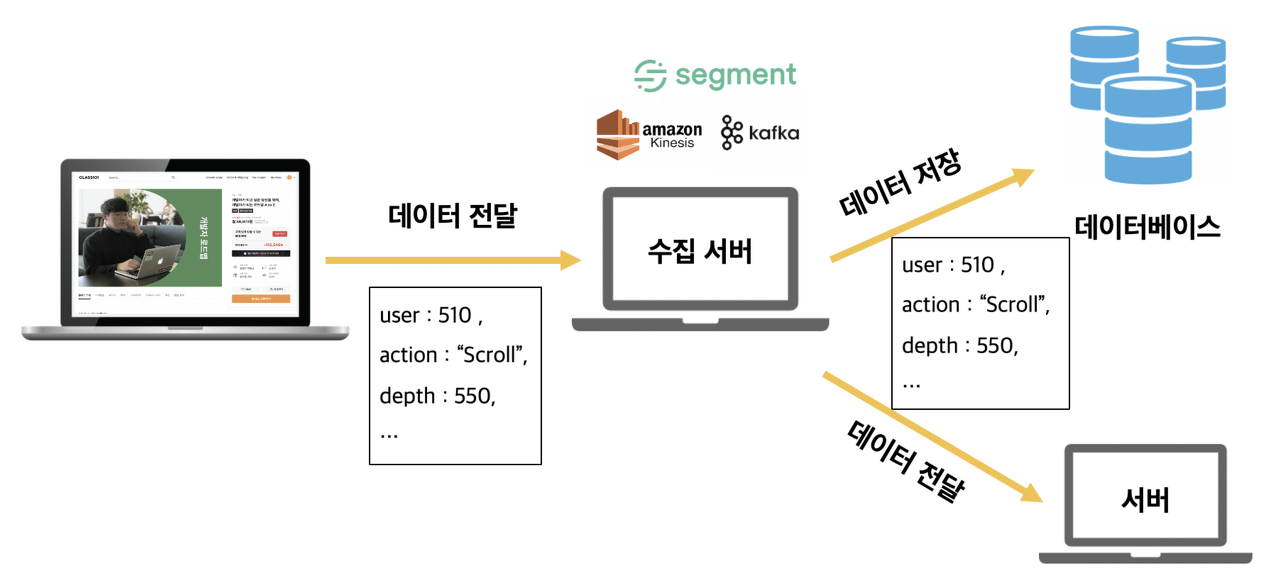
- Batch 성 작업이든, 실시간 작업이든 데이터를 모은다.
- Batch성 작업이면 snapshot을 뜨거나, 쿼리로 대상 데이터를 수집할 수 있을 것이고 (이 경우라면 수집서버 안 거쳐도 될 듯)
- 스트리밍 데이터면 어딘가 임시 저장소에 데이터를 모아놨다가 이를 한번에 drop하는 작업
e.g. AWS Firehose / 아니면 DIY
- 모은 데이터는 수집서버로 이동
- 예: Kafka Connect로 S3(Data lake)에 밀어버리기
- 수집서버로 이전된 데이터는 데이터 레이크에 임시 저장
- 데이터 웨어하우스에 쓰일 수 있는 형태가 아닐 것이라고 가정
- 물론 바로 쓸 수 있는 형태면 이 과정을 생략하고 바로 웨어하우스에 넣어도 되겠으나…
- 주기적으로 (혹은 특정 조건에 맞춰 — 이를테면 CloudWatch) 데이터 가공 파이프라인 구동
- e.g. AWS Glue
- 가공된 데이터를 적절한 웨어하우스에 저장
이미지 출처 및 자세한 아키텍쳐: https://rk1993.tistory.com/303 참고
다만 아래에서 언급하겠지만, 적당히 잘 정제된 형태로 데이터 레이크에 저장된 파일은 (e.g. csv, json), 바로 데이터 웨어하우스로 쓰일 수도 있다. 결국 사용하는 툴이나 의도에 따라 데이터 웨어하우스이냐 레이크냐가 갈리는 거지, 아주 엄밀한 구분 기준은 없음.
개인적인 생각이지만, 데이터 정제보다 일단 쌓고 보자는 마인드로 저장할수록 데이터 레이크에 가깝고, 실제로 그렇게 쓰게 되는 것 같다.
대표적인 데이터 웨어하우스들
사실 데이터를 담고 있는 어떤 저장소든 웨어하우스의 조건에 부합한다. 더 정확히는 OLTP보다 OLAP에 적합한 “대규모 쿼리 가능, 느린 레이턴시 OK” 의 특징이 있음
근래는 데이터를 쉽게 이전하고 보관할 수 있는 파일/오브젝트 기반의 웨어하우스가 증가하는 추세 같음 (느낌적 느낌)
Athena
언제 써야 할까요? 에 대한 문서 https://docs.aws.amazon.com/ko_kr/athena/latest/ug/when-should-i-use-ate.html
.parquet 형태로 떨어진 파일을 바로 읽어서 사용할 수 있다. csv , json 도 잘 먹는다. 어떻게 보면 SQLite랑 비슷한 느낌으로 써먹을 수 있는데…
위의 링크에서 확인할 수 있다시피, 가장 큰 특징이라면 비정형/정형 데이터 가리지 않고 많은 종류의 데이터 포멧을 그대로 인풋으로 사용할 수 있다는 점이다. 성능 그 자체가 훌륭하기보다는 다재다능한 느낌이라서 많이 쓰는 상황. 성능도 그냥저냥 쓸만함
- 다만 고부하 데이터웨어/메인으로 사용하기에는 분산으로 저장되어있는 S3 특성상 성능이 다소 부족한 문제가 생길 수는 있을 듯.
- 하지만 성능이 죽을 만큼 빨라야 할 일이 생각해보면 몇이나 되겠는가? 그런 소수 경우 빼고는 대다수의 사람은 편한 거 쓰고 싶어한다!
Athena가 좋은 이유.
Snowflake
https://data-engineer-tech.tistory.com/5
Athena와 비슷하다. S3를 소스로 해서 바로 SQL 날리고 온갖 분석 쇼를 할 수 있게 해준다.
특이점은 Cloud 최적화된 Serverless ”같은” 형태로 사용이 가능하다는 점이다. 왜 “같은" 이냐면, 실제로는 snowflake는 엄연한 instance가 존재하는 server이니깐…
아무튼 사용 쉽고 편리하고 성능도 좋은 Athena 같은 놈.
- server가 존재한다는 점에서 어떻게 보면 세부 설정이 가능한 것이 좋다. 그러니까, computation resource를 원하는 만큼 배치할 수 있음.
- 또 AWS-dedicated가 아니라서 플랫폼 덜 가리는 것도 일종의 장점.
- 남녀노소가 좋아하는 vs는 여기를 참조: https://www.firebolt.io/comparison/snowflake-vs-athena
Redshift
AWS에서 만든 웨어하우스 DB인데, 파일 based도 아닌것 같고, 겉보기에는 일반 DB와 별 차이는 없다. 하지만 내부 아키텍쳐 특성상 큰 데이터의 보관 및 쿼리에 적합하며, OLTP에 부적합한 특성이 있습니다( 레이턴시 김)
대용량 OLAP에 철저하게 적합하게 만든 DB입니다. 자세한 아키텍쳐는 여기를 참고.
- https://medium.com/@deepaksethi.ocp/aws-redshift-whitepaper-84e013272841
- https://velog.io/@jkim2791/Amazon-Redshift-와-MPPMassively-Parallel-Processing-에-대하여
- MBP, Columnar Data Storage, Data Compression 정도가 큰 내부 특징으로 보입니다.

그래도 redshift spectrum 같은 걸 만들어서 S3 같은 외부 데이터를 쿼리할 수 있도록 하는 기능도 있네요?
HDFS DB
얘는 파일을 source로 쓰지는 않기 때문에 주제에 부합하진 않지만 추가해 봄
하둡의 파일시스템인 HDFS 기반의 DB(HBase/Cassandra)에서의 DB. 클라이언트로 Hive를 많이 씀.
어쨌든간 결국 정제된 데이터를 저장하는 곳이니까, 그럼 데이터 웨어하우스다.
다만 그 수준이 꽤 고수준이라서, 데이터 소스를 편리하게 관리하기가 어려운 편이다. S3 파일을 마음대로 가져다 쓸 수 있는 Athena와 비교하면 그 차이가 더 극명하다. (점점 DB에 성격이 가까워지는 느낌…)
- 이 친구도 DB 특성상 Columnar 성격
이 외에도 많이 있습니다…
'개발 > Engineering' 카테고리의 다른 글
| AWS Step Functions (0) | 2022.10.31 |
|---|---|
| 대용량 로드밸런서 설계 (0) | 2022.07.24 |
| Workflow와 Distributed Tracing 툴의 구성요소 (0) | 2022.07.02 |
| MongoDB로 효율적인 자료구조 설계 하기 (0) | 2022.06.30 |
| 한 서버가 어떻게 16K 이상의 연결을 맺을 수 있을까? (0) | 2022.05.30 |