2021년 말, 이직을 결심하면서 많은 변화가 있었습니다. 기존 개발하던 On-demand 소프트웨어에서 대세를 따라 웹서비스 백엔드 개발로 갈아타게 되었는데, 당시 저에게는 몇년 전에 짜던 간단한 구조의 클라이언트 프로그램, 서버+DB+CDN 조합으로 완성되던 웹 서비스 개발이 전부였습니다(아래 이미지처럼).

출처: 링크드인 Engineering blog — Ah, the good old days of website development - nice and simple
하지만 몇년 사이에 세상이 확 바뀌었더라고요. 프로그램과 웹서비스들이 비대해지면서 많은 것들이 이원화되고, 이에 따라 새로운 분야의 개발직들이 생겨났습니다.
클라이언트 프로그램들만 하더라도, 바닥부터 개발하던 기존과는 달리 프레임워크와 이를 이용하여 콘텐츠를 생산하는 회사들로 이원화되었습니다 (예: 유니티와 게임회사들). 웹도 제가 기억하던 웹페이지 서빙과 api 처리를 동시에 하는 아주 단순한 구조에서 앱처럼 상태를 가진 React 프론트 + api를 처리하는 백엔드로 크게 이원화되었습니다. 모두 너무 생소한 개념들이 많이 생겨서 몹시 당황스러웠네요. 프론트엔드는 html 서빙 안 하고 프론트엔드 앱이라고 일컫고 있으며, 백엔드는 MSA 기반에 grpc에 …
너무 뒤쳐진 것 같아서 걱정도 들었지만 뭐… 모르면 공부하면 되죠! 그래서 어떻게 공부할까 고심 끝에, 저는 책을 읽기로 했습니다. 주변에 좋은 친구가 없어서 (^^…) 관심사를 같이 배우고 공부할 동료들은 없을지라도, 개발자 블로그 (velog 등)나 트위터로부터 들려오는 그런 사람들의 이야기들로부터 새어나오는 단서들 중 하나가 "책" 이었기 때문이죠. 책을 읽음으로서 지식을 흡수함을 물론, 훌륭한 사람들(책의 저자들처럼)과 같이 협업하지 못하더라도 그가 가진 사고방식과 철학을 오롯이 흡수할 수 있다는 건 정말 좋은 점이라고 생각합니다.
확실히 책을 읽으면서 많은 것들을 배웠습니다. 얼핏 알고만 있던 웹 서비스 개발 및 설계는 거의 바닥부터 다시 공부하다시피 했고, 이외에도 매니징 기법, 코스트 및 수요치 계산, 빠른 주기 개발 등 코딩 외적인 측면에서의 개발도 많이 배울 수 있었습니다.
꽤 배운 점이 많아서 앞으로도 매년마다 좋은 글들을 꾸준히 읽어가며 정리해 보려고 했는데, 올해는 그 양이 좀 많다 보니 상반기 내용을 잘라서 먼저 정리해 봅니다.
(오래 글을 쓰다 보니, 반말과 존댓말이 섞여 들어가 있습니다.)
읽었던 책들
1. The Go Programming Language
원래도 golang에 관심이 있어 공부해볼 생각이긴 했지만, 이직할 곳에서 golang을 main으로 쓰고 있다고 하여 후딱후딱 읽어치웠습니다 ... -_-;;
저자분이 Golang 팀의 일원이라고 하는데, golang의 철학을 적확하게 이해하는 데 도움이 될 것 같아서 선택했습니다.
책 자체 내용은 많지 않습니다. (B5 크기에 160 페이지밖에 안 됨). 그 중에서 language specific한 내용은 절반이 채 안될 것입니다. 그만큼 Golang은 그만큼 직관적이고 간단한 언어라는 생각이 드네요.
출퇴근 동안 짬짬이 읽어서 금방 읽을 정도로 내용 짧고 좋지만, 일부 자주 쓰이는 라이브러리(reflect) 부분은 따로 다뤄주지 않아서 직접 찾아봐야 합니다. 뭐 그런데 그 정도는 스택오버플로우 뒤지면 다 나오니까…
2. 맨먼스 미신
어떻게 보면 개발 서적이라기보다는 관리자로서의 소양과 관련된 서적인데, 생각보다 배울 점이 많았습니다.
우리 모두는 개발자이기 이전에 프로젝트 성공을 위해 뛰는 사람들이다. 이 책은 그 중간에서 발생하는 수많은 의사소통과 문제의 답답함에 대한 대답이 되어 주었다.
훌륭한 환경에서 직접 일해보지 않고도 그에 필적하는 경험치를 단 한권의 책으로부터 얻을 수 있었던 건 큰 행운이었다.
3. 시작하세요! 도커/쿠버네티스
클라우드 회사로 이직하게 되면서 도커와 쿠버네티스 좀 알아야 될 것 같아서 읽은 무난한 입문서.
바이블 정도로 읽어도 좋지만, 꼭 읽을 필요는 없이 hello world deployment 정도만 해도 충분할 것 같기도?
4. 14가지 AWS 구축 패턴
회사에서 온갖 AWS 서비스(Lambda, API Gateway, EKS 등등)를 쓰고 있어서, EC2 인스턴스 써본게 고작이었던 저는 꽤 겁을 먹었습니다 ^^; 부랴부랴 익숙해져야겠다 싶어서 일단 집어든 게 이 책이었습니다.
막상 사고 나니 회사 일이 바빠 거의 못 읽고 이제와서 읽게 되었는데, 첫 번째로 확실히 아마존은 철저하게 서버리스 플랫폼을 알고 있구나 생각이 듭니다. 고객이 개발만 하게 만드는 환경을 완벽하게 잘 알고 있고, 거기에 필요한 걸 너무나 잘 만들어 주는 것 같습니다. 두 번째로는 다양한 패턴에서의 아키텍쳐들과 여기에 필요한 AWS 서비스들을 친절하게 알려주고 있는 점이 좋았습니다. 세 번째로는 어떤 AWS 서비스를 써야 하는지는 알려 주지만 그게 어떻게 구동되는지는 알려주는 게 없는 게 아쉽네요. 하긴 그거 알려주면 책 두께가 다섯배는 더 늘어날테니...
딱 AWS 처음 쓰는 사람이 읽기 좋은 책인데, 막상 AWS를 잘 쓰려면 서버리스 플랫폼을 이해하고 있어야 하고, 그걸 이해할 정도가 되면 AWS 서비스를 어떤 걸 갖다 써야 할지 이미 다 알고 있다는 게 좀 계륵인 듯한 느낌입니다. 가볍게 읽을만 했습니다.
아, 하나 재미있는 점은 AWS 에서 제공하는 머신러닝 플랫폼 아키텍쳐였습니다. 의외로 관련해서 AWS가 많은 서비스들을 제공해 주고 있고, 이것들로 하나의 완성된 서비스를 이미 구현할 수가 있는 점이 인상깊었네요. 참고해 둘 만 하다고 생각했습니다.
5. Kubernetes in Action
이것도 출퇴근하면서 빠르게 읽었습니다. 책 양 자체가 많지 않아서 읽는 건 어렵지 않았고... 활용법이나 아키텍처 설계에 대한 내용이라기보단 단순 툴 활용에 대한 이야기라서 가볍게 읽었습니다 😄
6. 가상 면접 사례로 배우는 대규모 시스템 설계 기초
근래 수요가 많아진 높은 가용성, scalable하고 높은 트래픽을 감당할 수 있는 시스템을 어떻게 설계할지에 대한 바이블 느낌의 책입니다. 실제로 여러 다양한 패턴들에 대한 설명을 한 책으로 묶은 형태인데, 읽다가 보니까 글쓴이가 Alex Xu 더군요! 이분의 트위터에서 아키텍쳐 관련 좋은 글들을 많이 접한 기억이 있었는데, 이분이 쓴 책을 이렇게 접하다니 새삼 반가웠습니다.
사실 면접을 위해서 많이들 읽는 책이고 저도 그 용도로 샀지만, 정작 면접이 다 끝나고서 읽게 되었는데 너무나 좋은 내용들이 많아서 놀랐습니다. 단순 아키텍쳐 설계 이외에도 어떻게 효율적으로 요구사항을 파악하는지까지 완벽한 가이드가 되어 있습니다. 개인적으로 분산 시스템을 넘어서서 여러 분야에서 쓰일만한 설계의 기본 상식들이 들어 있어 상당히 추천할 만한 책이라는 생각입니다.
개중 인상 깊었던 것은 CPU 캐시, RAM 캐시, SSD 랜덤액세스, HDD 랜덤액세스와 같은 세부 수치를 예를 들며, 이런 요소들을 이용하여 추상적인 수치를 내어 설계를 진행하는 내용과 웹 파서 설계에 대한 내용(성능 향상을 위한 보다 구체적인 캐시의 제시, 예외적인 사항 및 기능 확장성에 대한 고민)이었습니다. 세부 구현사항을 평소 깊이있게 생각하지 않던 저에게 있어 꽤 생각해 볼 내용이 많았습니다. 말 그대로 “more than architecting” 입니다.
아직 읽지 못한 서적들
본래 ML쪽으로 해보고 싶은 게 있어서 관련 서적들을 읽으려고 했는데 그렇지 못한 것들이 좀 많네요. 지금도 다른 읽고 해야 할 것들 때문에 우선순위가 꽤 낮아져 있는 상황이라, 언제 읽게 될지는 모르겠습니다 😅
(개인적으로는 10, 11, 12번 책들을 최우선으로 읽어보려고 하고 있습니다.)
1. 신경망과 심층학습
예전부터 데이터과학 분야에 있어서 정말 좋은 기본서적이라고 들어왔다. 겉핥기로 읽었을때도 흥미로운 내용이 많아, 내 토이프로젝트 작업할 욕심도 있어서 주문까지 해놓고 읽어보려고 했으나... 읽어보기도 전에 우선순위에서 밀려나 버렸다 😂 나중에 읽어야지.
2. Advanced Programming in the UNIX
나는 유닉스 시스템을 쓰면서 유닉스에 대해서 정작 잘 모른다 (...) 아무래도 기초를 닦을 필요가 있다고 생각해서 읽을 준비까지 다 해 놨는데 물밀듯 쏟아지는 k8s 및 도커 공부에 밀려서 결국 못 봤다 (...) 나중에 봐야지.
3. Linux Kernel Development
리눅스 환경에서의 보다 심층깊은 개발을 위해서 읽어보려고 했으나... Advanced Programming in the UNIX 책에 우선순위가 밀렸다 ^^; 나중에 읽어야지.
4. Deep Learning - Ian Goodfellow
데이터 사이언스에서 필수적으로 사용되는 개념인 정보이론에 대한 기본서, 이전에 읽었으나 정말로 80% 정도는 이해를 제대로 하지 못하고 넘어간 부분이라 다시 읽어볼 생각이었다 (...) 하지만 하는 일이 다시 데이터 사이언스쪽과 멀어지면서 우선순위가 내려왔다. 나중에 다시 읽어야겠다.
5. Information Theory, Inference, and Learning Algorithms - David MacKay
위와 마찬가지 이유로 미뤄짐.
6. 실전 시계열 분석
마찬가지 이유긴 한데, 시계열이라는 굉장히 실용적인 문제를 가지고 재미있게 다뤄놓은 것 같아 빠른 시일 내로 읽어보고 싶다.
7. 실무 예제로 배우는 데이터 공학
아키텍쳐를 넘어서, 실제 데이터 엔지니어링에서 사용하는 툴을 직접 사용하여 실무 환경 구축하는 법을 알려준다. 아무래도 이쪽 분야에서 종사하는 게 아니면 해볼 수 없는 경험을 책을 통해서 쌓을 수 있다는 것 자체가 굉장히 흥미로운 일이기 때문에, 읽는 걸 넘어서 한번 따라해 봐야 할 텐데 말이지 ㅎㅎ...
8. DDD Start!
도메인(비즈니스) 주도 설계에 관한 책인데... 품절되었네요 😅 오래 되어서 그런가, 수요가 없어서 그런가, 아니면 그렇게 핫한 책이었을까...
그래도 인터넷에 관련 자료나 읽을거리들이 많아서 어쩌면 애써 서적까지 챙겨 읽을 필요가 없을지도 모르겠네요.
9. Clean Architecture
잘 알려져있는 Clean code의 아키텍쳐 버전인 듯 합니다. 클린코드(리팩토링) 책이 그랬듯이, 이것 또한 읽어두면 큰 도움이 될 것 같아서 시간 날때 조금씩 읽어 보려고 합니다.
10. 데이터 중심 어플리케이션 설계 (Designing Data-intensive Applications)
근래 수요가 많아진 빅데이터 시스템을 어떻게 설계할지에 대한 바이블 느낌의 책이라고 하여, 이것도 시간나면 읽어보려고 합니다. 그래도 이제 목차 보니 좀 익숙한 기술들이 많이 보여서 가볍게 읽을 수는 있어 보입니다. 메시징 시스템이나 분산 시스템에서의 장애극복, 컬럼 지향 저장소 등...
11. Software Design at Google
맨먼스 머신이 추상적인 원칙 위주로 이야기한다면 이건 보다 구체적인 이야기들로 되어 있을거라고 생각합니다. 단순 보여주기식 내용이 아니라 실제 프로젝트 설계 수립 및 매니징 관련 경험들을 책에서 다루고 있는 걸 보고 이거다! 싶었습니다. 좋은 내용이 있을 것 같아, 빨리 읽을 수 있기를 기대하고 있습니다 ㅎㅎ.
12. Refactoring 2
이건 원래 제일 먼저 읽기 시작하던 건데 다른 공부들 하다 보니 한참 후순위로 밀려서... 출퇴근 하면서 패드 미니로 어찌어찌 읽고 있습니다. 생애 최초로 읽는 원어 기술서라 읽는 속도가 느리네요 …
이런저런 내용이 많지만 결국은 feature extraction, pack related code together가 대부분의 모토를 차지합니다. 이를 뒷받침해주는 다양한 예시들이 많은 것이 장점.
이거 말고 다른 책으로 읽는다면 Clean Code 읽어도 무방할 듯.
읽었던 개발 관련 글들 (2022년)
새로운 분야로 들어가게 되면서 관련 책도 열심히 읽었지만, 어느 순간부터 각종 기업들과 여러 “재야의 고수”들이 쓴 글들을 읽기 시작했습니다. 고성능 구현에 대한 아키텍처 설명이나, 서비스 장애에 대한 에세이들이 그러한 글들이었습니다.
책에서 다루는 내용은 얕고 넓어 “그런가 보다" 하면서 그냥 읽어들이는 게 전부였는데, 개발 관련, 특히 이슈들을 다룬 글들은 그보다 훨씬 근본적인 문제들을 다루고 있어 좁고 깊었습니다. 그런데 재미있는 점은 결국 그 맨바닥에서는 컴퓨터 구조와 운영체제로 귀결됩니다 ㅎㅎ. 동시에 이런 글들로부터 여전히 배울게 많다는 생각을 하게 되었고, 그런 글들을 3월 즈음부터 찾아 읽게 되었던 것 같네요.
1. Golang이 효율성을 달성하는 방법
고랭만큼 사용하기 편하고(문법의 허용성도 좋고, 편리한 덕타이핑에, GC에다가, 동적타입 추론까지...!) 성능 그럭저럭 잘 나오는 언어가 없다시피 한데, 어떻게 그럴 수 있는지에 대한 몇가지 의문점이 있어 이것저것 좀 찾아봤었습니다. 그러다 보니 고랭에서 내부적으로 사용자가 신경써줘야 할 것들을 알아서 빠르게 처리해 줄 수 있도록 설계한 부분이 생각보다 많다는 것에 놀랐습니다. 사용자가 실수없는 코드를 짤 수 있도록 케어해주는 Rust 대비해서 추구하는 바가 정반대라는 것도 재밌네요.
2. Kafka가 고성능을 달성하는 방법
단순 분산시스템이라서 빠르겠거니 생각했는데, DMA와 연계해서 커널 콘텍스트 스위칭을 줄이는 신박한 설계에 다시 놀랐습니다. 로우레벨에서의 성능 경합 같은 건 감으로 어떻게 알 수 있죠... OS팀에서 일 해야 알 수 있는거 아닌가...
3. Nginx가 고가용성을 유지하는 방법
단일 스레드만 생성하는 특징을 가진 event-driven인 것은 알았는데, 이게 구체적으로 뭐하는 건지는 지금까지 한번도 깊이있게 살펴보질 않았었습니다. 그러다가 면접에서 관련 질문 들어오니 탈탈 털리게 되더라고요 😭...
덕분에 잊고 있던 select() API를 기억해 낼 수 있었습니다. 다시 보면 별 것 아닌데, 어떻게 보면 콘텍스트 스위칭과 같은 로우 레벨에서의 설계를 주요 문제로 파악해 낸 통찰력은 참 대단한 것 같다는 생각이 듭니다.
4. Domain Driven Dev, 그리고 이벤트기반 아키텍처 구축하기
DDD 책을 읽지 못한 대신 인터넷에 쓰여 있는 여러 글들을 참고해서 읽어보기로 했습니다. DDD를 실현하기 위해서 많이 쓰는 것들이 데이터 driven dev, event driven dev, CQRS 등이 있습니다. 그리고 제가 읽은 글에서는 이벤트기반 아키텍쳐를 적극 활용한 모습이었습니다.

글을 단 하나로 요약하자면 이 그림이 될 것 같네요.
처음에 이 글을 읽고 또 큰 깨달음을 얻었던 기억이 있습니다. 지금까지 타 서비스(마이크로시스템)을 트리거하기 위해서 메시지를 보낸다는 생각을 했었지, “로그"와도 같은 “이벤트"를 날려서 타 서비스를 동작시킨다는 생각은 해본적이 없었거든요.
5. Django와 ALB의 502 오류 대모험
이후에 별도 Django는 과연 느린가? 포스트로 정리하긴 했는데, django 는 파이썬이라 나쁜 언어야! 라고 생각하던 제 고정관념에 큰 변화를 준 글이었습니다. 장고탓을 할게 아니라, RDB 떡칠에 도메인 로직과 분리가 전혀 안 되어 있는 개떡같은 제 설계가 문제였던 걸로... ^^;
6. 네임스페이스와 cgroup
Docker 내부 원리 공부한다고 잠깐 봤었네요 ㅎㅎ. 세부 구현 같은것도 보고 싶었는데 (PCB에 영향을 준다거나 하는 것도 확인을...), 딱히 확인은 못했고, 아마 완전히 커널단에서 처리하는 것으로 보이는 것 같네요. https://www.nginxplus.co.kr/doc/guide/what-are-namespaces-cgroups-how-do-they-work/?fbclid=IwAR0QGrygL7-fMrH6PvFuFLTCMkW0w_T0oUkebtT4gn60jBQ5k4onZ9021WM
7. 딥러닝 기반 세차 인증 자동화 모델 개발
소카 포스팅입니다. https://tech.socarcorp.kr/data/2022/04/18/develop-model-classifying-washed-car.html
올해 주력으로 밀던 클라우드와 고랭에서 벗어난 딥러닝 관련 이야기지만, 이론적으로 그렇게 어려운 이야기는 없고 편하게 읽을 수 있는 테스트 설계와 같은 이야기들이 많아 읽기도 쉽고 배울 것이 많았습니다.
- 모델, 프레임워크 <<< 데이터의 중요성
- 성공과 실패에서의 세부 케이스 분석, 그리고 아예 레이블이 없는 경우
- 모델별 성능이 다른 이유의 세부 설명 (모델이 주목하는 feature와 데이터 셋에서 파악하고자 하는 feature의 좋은 분석!)
- No label (Rejection) 의 경우에 대한 접근 방법으로, certainty 대신 별도의 open set recognition을 사용한 점
8. DynamoDB와 Spanner 논문
언젠가 읽어봐야지 하고 벼르다가 드디어 읽었습니다. 그동안 On-premise 서비스 정도밖에 안 사용해봐서 저렇게 클러스터 단위로 폭넓게 설계하는 걸 해본 적도 해볼 일도 없었는데, 논문은 그러한 내용들의 연속이어서 어떻게 보면 고통스러웠고 (...), 다르게 말하면 배울 게 많았습니다. SPOF를 피하는 설계, continous hashing, 분산 시스템에서 consistency 확보하기 등 많은 내용들에 대해서 배울 수 있었습니다.
(별도 포스팅으로 내용을 “얕게” 정리해 두었습니다)
9. TAO(Facebook social graph storage) 및 소셜 네트워크 서비스 아키텍쳐
좀 된 내용이기도 하고 페이스북에 국한된 아키텍쳐이긴 하지만, 나름 high-throughput 소셜 미디어 정수들이 들어있습니다. look-ahead 캐시는 기본이요, 필요하면 consistency를 희생하며 캐시를 사용하는 경우도 상정하고, scalability를 위한 consistent hashing, 그리고 최소한의 데이터들로 최대한의 효용을 발휘하기 위한 그래프 기반 아키텍쳐까지.
그 중에서도 핵심은 graph 기반에서의 캐시일 겁니다. look-ahead 캐시로는 부족했던 성능을 그래프 기반 아키텍쳐로 보고, 이를 쿼리하고 캐시하도록 하는 발상의 전환을 통해 훨씬 캐시의 활용도를 높였습니다.
더 나아가서는 수천명의 팔로워가 존재하는 상황에서 글을 쓸 때 실제로 발생하는 트래픽의 크기와, pull과 push 방식의 양단성 등 고민할 부분이 많습니다.
당연한 듯 하지만, 처음부터 페이스북을 만든다면 어떻게 했을까 고민하며 읽으면 배울 게 참 많은 논문이라고 생각이 됩니다. 딱 아키텍쳐 인터뷰에 써먹기 좋은 논문.
- 네이버 D2에 잘 정리된 글이 있습니다. https://d2.naver.com/helloworld/551588
- 논문: https://www.usenix.org/system/files/conference/atc13/atc13-bronson.pdf
- 마찬가지로 면접에서 딱 써먹기 좋은 내용들이 많은 듯.
10. 클라우드 가상화 기술 논문(Borg, Firecracker)
이것도 언젠가 읽으려고 벼르다가 드디어 읽었습니다. 열심히 읽어 별도 포스팅으로 정리해놓았고, scalable한 컨테이너 가상화 시스템에 대한 고민, 그리고 이를 향상시키기 위해서 어떤 기술들이 쓰였는지 아주 deep 레벨부터 알 수 있는 좋은 기회였습니다. 역시 이런 고급진 내용은 정리된 글로 찾기 힘들고 직접 논문 찾아 읽어야...
11. AWS Well-Architectured framework
이건 우연히 인터넷을 뒤지다가 봤는데 단순 AWS를 벗어나서 분산컴퓨팅 및 아키텍쳐 설계 관점에서 너무 좋은 자료들이 많았습니다. 어지간한 책보다 이거 하나 제대로 정독하는 게 설계 측면에서 내공 쌓기 너무 좋아 보입니다. 마치 brain dump되는 기분.
- AWS Well-Architected Framework
- 어쩌면 이거 “데이터 중심 어플리케이션 설계" 책과 궤를 같이 할지도?
12. Cluster ID generator
언젠가 ID 생성기가 꽤 중요한 설계 내용인 적이 있어서, 해당 내용을 조금 유심히 읽어 보았습니다. 내용 자체는 간단한데, 그럼에도 불구하고 고민해 볼 내용들이 좀 있더라고요. 제일 참신했던 건 cluster 단위에서 unique 해야 함에도 불구하고, 노드 간 통신이 필요없도록 하는 일종의 발상의 전환이었습니다.
이 내용 또한 포스트로 별도로 정리해 두었습니다.
13. React 멈춰!
https://seokjun.kim/time-to-stop-react/
사실 이건 리액트 대신 DOM 깎는 걸 좋아하던 제 개인적인 취향(?)을 확고히 하고자 읽었는데, 생각보다 재밌게 읽은 데다가 React의 근본적인 등장 배경에 대한 이해까지 할 수 있어 같이 싣어 두었습니다. 리액트와 웹앱 생태계가 커지면서 발생하는 서치엔진의 문제를 해결하기 위해 SSR(Server side rendering)이 생기고, 결국 이는 서버 측에서의 무거움을 가중시킨다는게 핵심 요지인데, 뭐 그것도 그렇지만 엔진 자체도 무겁고 의존성도 이리저리 커져서, 미니멀리즘을 중시하는 저한테는 썩 마음엔 안 들어요... 물론 웹앱 기반으로 개발을 해야 한다면 대안은 없다시피 합니다.
14. Data Loader 설계에 대하여
https://d2.naver.com/helloworld/3773258
이번 건 또 오래간만에 데이터 엔지니어링이네요. 몇백GB, TB에 달하는 대규모 자료들을 쉽게 가공 및 분석하기 위해서 어떠한 고민을 했고, 이에 걸맞는 어떤 툴을 선택했고, 이에 따른 문제의 원인, 분석, 개선방안에 대한 이야기들이 있습니다. 클라우드와 가깝기도 하고, 빅데이터를 다루는 일은 언제든지 환영(?)이라서 이런 글 또한 언제든지 읽어두려고 하고 있습니다. 다행히 내용 자체는 꽤 generic 해서 어렵지 않게 읽을 수 있었습니다. column 단위 저장의 이유, 랜덤 샘플링에 대한 전략, 평가용과 학습용에 대한 복원/비복원 접근 차이 정도가 인상깊었네요.
15. mongoDB 정의와 NoSQL
https://meetup.toast.com/posts/274
저는 그동안 RDB가 아니면 NoSQL로 치부하는 단순한 사고(?)를 가지고 있었는데, 실제로 다루어야 하는 데이터는 그렇게 간단하지 않죠. 복잡한 도큐먼트 형 데이터도 있고 빠르게 접근해야 하는 키 - 값 데이터도 있고 다양합니다. 그런데 저는 그것을 그동안 단순하게 다 똑같은 NoSQL 아니야~ (?) 이렇게 치부하고 있었습니다. 하지만 각각의 용도에 대해서 알아가다 보니 이러한 제 생각이 짧았다는 걸 다시금 깨닫게 되네요. 데이터의 형태에 알맞는 데이터베이스를 쓰는 것과, 역으로 데이터베이스에 알맞게 데이터 구조를 모델링 하는 것은 분산시스템 환경에서 몹시 중요한 능력인 것 같습니다.
16. Facebook timeline: Power of Denormalization
https://engineering.fb.com/2012/01/05/web/building-timeline-scaling-up-to-hold-your-life-story/
비정규화(Denormalization)에 대한 이야기입니다.페이스북과 같이 굉장히 복잡하고 큰 규모의 데이터를 다루는 경우에는 JOIN을 수행하는 비용 자체가 엄청 큼을 이야기하며(랜덤 IO가 발생하기 때문에), 이를 해결하기 위해 제시한 denormalization에 대한 이야기입니다. 하지만 단순히 이를 수행하는 것만으로도 굉장히 부담이 크기 때문에, 추가적으로 캐시를 사용하여 안정적으로 수행할 수 있었다는 이야기입니다. 보통 데이터 정규화를 만능으로 가져가곤 하는데, 이와 반대되는 행위를 해결책으로 들고왔다는 점이 꽤 인상깊었습니다.
17. Facebook’s photo storage
https://www.usenix.org/legacy/event/osdi10/tech/full_papers/Beaver.pdf
이번 논문도 페이스북 논문입니다. 어떻게 규모의 사진 이미지를 관리할 수 있는가에 대한 이야기인데(어떻게 최적화 했는가), 메타데이터 읽기/쓰기에서 병목이 확인되어서 거기에 캐시를 달았다는 것이 핵심 내용입니다. 비단 그 내용 말고도 전반적인 디자인이 꽤 모범적(?)이고, Directory 서비스를 만들어 미리 store 공간을 할당받는 아키텍쳐나, 공격 방지를 위한 cookie randomization 등 재미있는 요소들이 많아 읽어보기 좋은 것 같습니다. 비슷한 논문을 많이 읽어놔서 점점 읽기가 수월해지네요.
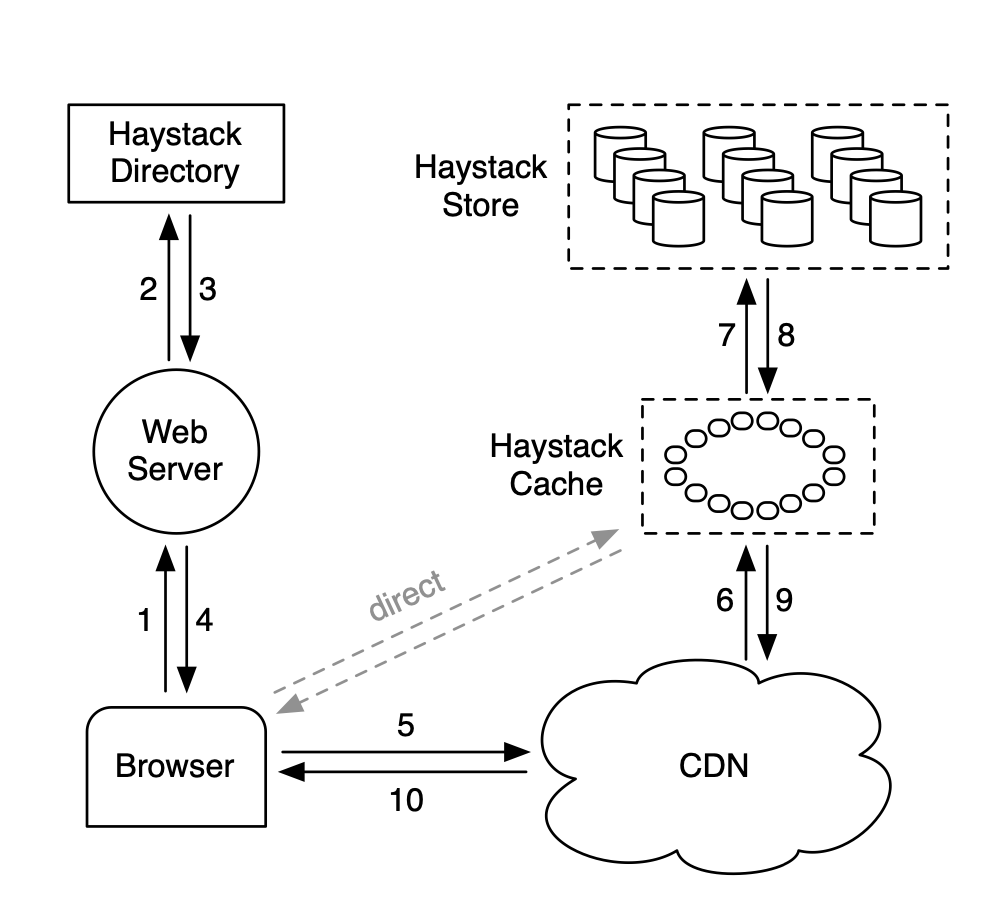
18. 다양한 회사의 아키텍쳐들
http://highscalability.com/amazon-architecture
http://highscalability.com/flickr-architecture
https://engineering.linkedin.com/architecture/brief-history-scaling-linkedin
http://highscalability.com/blog/2015/11/9/a-360-degree-view-of-the-entire-netflix-stack.html
http://highscalability.com/google-architecture
연관 자료가 있길래 들어가서 읽어 봤습니다. 이제는 연식이 좀 된 회사들이다보니 약간 낡은 (?) 요소를 사용하는 곳도 있지만 공통적으로 서비스간의 coupling을 줄이고, 캐시의 적극적 활용, RDB/NoSQL을 혼합해서 잘 활용하고 있다는 점이 공통점이었습니다. 아마존 같은 경우는 매니징에 관한 내용도 어째서인지 같이 들어있더라고요.
페이스북 같은 곳은 기존 구성요소를 마개조하는 튜닝까지 동원해서 서비스를 했기에 거기에 비하면 밋밋한 편이지만 그래도 가볍게 읽기 좋았습니다 (?)
- 플리커 같은 경우에는 50% rule 과 같이 peak에 대비하고자 하는 여러 모습들이 인상적이었습니다.
- 링크드인은 페이스북과 유사하게 비싼 그래프 쿼리를 위한 별도 서버/캐시를 설계해 두었더군요.
- 왓츠앱은 회사 값어치에 대한 긴 서두(?)와 함께, 모니터링 스탯들에 대해 상세히 언급해 두었더라고요. 그리고 실 트래픽을 bypass시켜 프로덕션으로 가기 전에 테스트 하는 것도 인상깊었습니다. (일종의 A/B test) Lock Contention 체크를 꼼꼼히 하고 이를 극복하는 과정 또한 인상깊었습니다. 그리고 Erlang 덕후들
- Google의 경우 컴프레션의 적극적 활용, 인프라 재구성에 하둡 적극 활용 등이 인상깊었습니다.
19. Uber Architecture
http://highscalability.com/blog/2015/9/14/how-uber-scales-their-real-time-market-platform.html
Uber에서 특이할만한 점은 극한의 가용성, 확장성(scaling) 을 고려한 설계였습니다.
- 가용성을 높이기 위해서 드라이버의 모바일 기기를 일종의 분산 백업 장치(!)로 활용한다고 합니다.
- “Make everything killable”이 꽤 인상깊었습니다. 맞는 말인게, 경험상으로도 제일 최악의 상황은 hang 상태에서 아무런 조치를 취할 수 없는 경우였습니다. 왜냐하면 crash에 대해서 대처를 해도 hang 상태에서는 대처가 안 된 상황인 경우가 많아 정상 작동을 보장할 수가 없고, 더 문제는 비정상인데도 kill되지 않아 즉각적인 처리가 안 되어서 availability에 가장 큰 영향을 끼치는 경우가 많았던 기억이 있네요.
- Gossip system을 전체 아키텍쳐에 이렇게 적극적으로 반영한 건 꽤 신기합니다. 아무 서버에 리퀘스트를 올리면 적합한 서버로 redirect 해주는 구조라고 합니다. 덕분에 scaling이 매우 수월하고(그냥 시스템 하나 올려서 얹어놓으면 끝이니), 다만 downside로 라우팅에 시간을 다소 뺏길 수 있다고 하네요.
- 공간의 단위에서 sharding하기 위해서 각 구역을 나누고 hash하여, 각 구역별로 서비스 단위를 쪼개는 방식으로 구성했다고 합니다. 공간을 적절하게 나누었다는 전제와 driver이 보통 evenly하게 존재할 것이라는 가정 하에서 괜찮은 접근일 것 같습니다.
- 이외에도 현재 운행중인 드라이버도 추적하고, 공항과 같은 곳에서는 수요를 순서대로 처리하도록 하는 등의 여러 요구사항에 대한 파악 또한 흥미로운 점이었습니다.
20. Pinterest 아키텍쳐
서비스 초창기 개발부터 성숙해지는 단계까지 도달하면서 겪었던 여러 Lesson들에 대해 잘 정리되어 있어 재밌게 읽었습니다.
- 올바른 아키텍쳐는 부하에 알맞게 수평적 확장이 가능한 아키텍쳐 — 당연한 사실이지만 어렵습니다
- 필요한 DB 소프트웨어를 선정하는 기준들
- 클러스터링과 샤딩 두 관점에 대해서 — 적어도 DB에서만큼은 샤딩이 훨씬 낫겠다는 생각이 들었습니다. 클러스터링 알고리즘/내부 데이터 자체가 복잡한데다가 SPOF 되는 경우도 있어 state가 많은 경우에는 불리한 듯.
- 필요할 때마다 수동 샤딩. — 이건 다소 낡은 기술이긴 하지만, 어쩌면 consistent ring + automatic resharding 하는 것에 비하면 manual sharding이 개발 측면에서 훨씬 더 싸게 먹힐지도 모른다는 생각도 듭니다. 그리고 특정 샤드에 과부하가 걸리는 경우라면 consistent ring보다는 이 쪽이 더 직접적인 해결책이 될 지도. 아주 구체적으로 어떻게 샤딩했는지, 샤딩 키(데이터모델)는 무엇인지 까지는 안 나오네요.
- 캐싱 — 역시 memcache + redis 조합은 무적입니다.
이외에도 소소하게 읽은 아티클들은 많지만, 그 중 인상깊었고 이해하는데 시간을 투자했던 것들이 아마 위와 같은 것들이었을 겁니다.
개인적으로 “문제"가 있었고 이를 “해결"하기 위해 투자한 노력이나, 혹은 제시한 해결 방안들에서 새로운 점을 많이 배울 수 있었습니다. 이러한 점들은 책에서는 잘 다뤄주지 않는 것 같더라고요. (그나마 가장 가까웠고 많은 정보를 제시해 줬던 책이 가상 면접 사례로 배우는 분산시스템 기초)
아무튼 이것들을 읽으며 기존과는 다른 분야의 개발지식을 많이 익힐 수 있었습니다. 하반기 결산은 여기까지 하고… 이제 미뤄뒀던 책을 읽어야 하지만 사이드 프로젝트를 하느라 또 많이 바쁠 것 같네요 😭
'개발 > Essay' 카테고리의 다른 글
| 웹 서비스 백엔드 바닥부터 개발한 후기 (0) | 2022.08.06 |
|---|---|
| 개발자로 살면서 겪은 것들에 대한 이야기 (0) | 2022.08.01 |
| 효율적인 업무를 위한 15분 규칙 (0) | 2022.04.30 |
| [개발회고록] bmx2ogg와 Rhythmus (0) | 2022.04.16 |
| 재직 중인 회사에서 연봉 협상하기 (0) | 2022.03.01 |