이전에 Bison/Flex로 파서 관련 작업을 한 적이 있어, 해당 내용을 정리할 겸 써 둡니다.
Parser이란 무엇인가?
먼저 구체적인 개념을 들고 가기 전에, Parser이 무엇인지에 대해서 짚고 넘어가고자 합니다.
먼저 우리가 통상적으로 우리가 말하는 Parser은 “별도의 Lexer이 없는 구문 분석기" 정도가 됩니다. 즉 string을 입력으로 받아 AST tree가 output으로 나오는 것입니다. 단순 하드코딩한 파서 한 번쯤은 짜보신 적 있으시잖아요? ㅎㅎ
하지만 보다 복잡한 Parser의 경우 “token을 주어지는 syntax에 따라서 처리하는 구문 분석기" 의 역할을 수행하게 되고, 이러한 token을 생성하는 작업을 하는 Lexer이 별도로 존재합니다. 사실 Tokenizer이 따로 있고 거기에 Lexer이 의미를 덧붙이는 구조가 될 텐데, 보통 Lexer이 그 두개를 다 해주는 구조입니다.
따라서 Lexer과 Parser는 유기적으로 연동될 수밖에 없습니다. 왜냐면 결국 Lexer의 output이 Parser의 input이 되거든요. 그래서 Lexer에 변동이 있으면 자연스럽게 Parser에도 반영이 되어야 합니다. 그리고 (Parser 알고리즘에 따라 다르지만) 일반적으로 Parser의 문법이 추가되면 이에 해당하는 state table도 같이 따라서 모두 갱신을 시켜줘야 하고요. 또한 parser의 문법에 오류가 있다면 미리 검증을 해 볼 필요가 있고요. (말이 안 되는 문법을 써놓는다던가…)

그런데 그걸 언제 다 짜고 있어요?
Parser generator
다행히도 이러한 Parser을 자동으로 만들어 주는 Parser Codegen (통칭 Parser generator)들이 존재합니다. 무려 Wikipedia에 방대한 문서까지 가지고 있습니다!

그리고 Bison/Flex는 이 중에서 오래전부터 쓰여온 잘 알려진 유서깊은 parser 중 하나입니다. 저도 몇번 써 봤기 때문에(…) 하필 이 놈으로 글을 써 봅니다.
다만 해당 글에서 보이는 것처럼 Parser generator들이 굉장히 많기 때문에 자신이 개발하고자 하는 문법의 제약사항이나 특징을 잘 알아보고, 그에 맞는 적합한 것 찾아 쓸 필요가 있습니다. 고려해야 할 요소들이 Parsing algorithm이나 Output language 정도가 될 것 같네요.
Note: 결국 이러한 Parser generator들은 CDF의 일종이고, 기본적으로 BNF의 표기 방식을 따릅니다. 굳이 저 개념을 아는 것보다는 실제 bison 코드를 한 줄 보는 게 더 와닿기 때문에 일단 그렇구나 하고 넘어갑니다.

딱히 코드는 없지만 (…) 실제 사용례 몇 개랑 함께 설명을 써 놓겠습니다.
Parsing algorithm들
다양한 파싱 알고리즘들에 대해서 알아보겠습니다. 모든 파싱 알고리즘을 다루지는 않고 대중적인 알고리즘들 개요만 쭉 훑고 넘어갑니다.
더 세부적으로는 Formal Grammar/Theory(형식언어이론)에서부터 시작하는 내용이지만 PL쪽 내용은 대충 스킵하고 넘어갑시다
LL/LR/LALR 파서
일반적으로 Yacc로 이루어져 있고, 형식언어 이론을 바탕으로 만들어진 파서입니다.
여기서 파서 하나하나를 간단하게 알아보면,
- LR 파서: Left to Right, rightmost derivation. 즉 왼쪽부터 토큰을 읽어 처리하는 형태의 파서. 보통
LR(1)형태로 표현되는데, 이는 뒤에 있는 1개 토큰만을 보고 파싱을 수행한다는 뜻. 따라서 Linear Time Complexity가 보장됨.- 이후에 이를 효율적으로 수행하기 위한 “Table”을 추가한 SLR이 생깁니다. 근본적으로는 별 차이 없음.
- LL 파서: Left to right, leftmost derivation. 마찬가지로 왼쪽부터 토큰을 읽으나, 가장 큰 차이점은 Top-down 형태라는 특징입니다. 즉 최종 형태의 심볼이 가장 먼저 결정되고 세부 심볼이 만들어지는 방식이 됩니다.
- 현재 위치의 오른쪽 심볼(rightmost)을 k개 읽어가며 판단하는 Bottom-up과는 달리, 왼쪽(leftmost)의 k개 심볼을 읽으며 최종 심볼을 생성하는 것이 특징이며, 문법에 ambiguous가 있을 시
LL(1)로는 수행이 불가능하여LL(k) (k > 1)형태로 수행되어야 해서 효율적이지 못합니다.
- 현재 위치의 오른쪽 심볼(rightmost)을 k개 읽어가며 판단하는 Bottom-up과는 달리, 왼쪽(leftmost)의 k개 심볼을 읽으며 최종 심볼을 생성하는 것이 특징이며, 문법에 ambiguous가 있을 시
- LALR 파서: Look-Ahead LR 파서,
LALR(k) = LA(k)LR(0)형태로 표현되곤 합니다. 일반적으로LALR(1)형태가 사용되며, 토큰을 “Lookahead” 하여 파싱을 수행하게 됩니다.- LR 파서와 근본적으로 동작하는 방식은 같지만 가장 큰 차이는 “상태 테이블"을 사용한다는 것입니다. 그래서 중복된 State들을 압축시켜서 훨씬 상태 테이블이 간소하다는 특징이 있습니다. Wikipedia의 문서를 참고하시면 더 도움이 될 듯.
- LALR parsers have the same states as SLR parsers, but use a more complicated, more precise way of working out the minimum necessary reduction lookaheads for each individual state. Depending on the details of the grammar, this may turn out to be the same as the Follow set computed by SLR parser generators, or it may turn out to be a subset of the SLR lookaheads. Some grammars are okay for LALR parser generators but not for SLR parser generators. This happens when the grammar has spurious shift/reduce or reduce/reduce conflicts using Follow sets, but no conflicts when using the exact sets computed by the LALR generator. The grammar is then called LALR(1) but not SLR.
Top-down parsing의 모습입니다. 최종 심볼 (root)의 생성 번호가 1번인 것을 알 수 있습니다.
아무튼, 이 계열의 파서에서 최종적으로 많이 쓰이는 유형은 LALR이 됩니다. 이후에 state 충돌을 회피하기 위한 GLR까지 덧붙여지면서 더욱 강력해집니다.
하지만 이건 아직 파서의 종류에 대해서 맛보기 수준의 설명이고, 아직 핵심 개념을 설명하기 위해서는 “상태 테이블"이라는 개념에 대해서 알아볼 필요가 있습니다.
Shift-reduce 파서
아까 “상태 테이블"이라는 것이 있다고 이야기 했는데, 거기에 더해서 지금까지 읽어들인 상태(심볼)를 계속해서 저장하는 “상태 스택"이라는 것이 존재합니다. 스택과 테이블, 그리고 Lookahead 심볼을 기반으로 하여 파서는 다음 상태를 어떻게 정할지를 결정하게 됩니다. 이를 Shift-reduce 파서라고 이야기합니다.
그리고 상태를 결정하는 2가지 방법이 크게 Shift와 Reduce가 있습니다.
- Shift: 현재 상태를 스택에 쌓고, 다음 상태로 이동
- Reduce: 현재 문법이 모두 완성되었기 때문에, 스택에서 몇 개의 상태를 빼고 이를 상위 부모 심볼로 대체함.
Shift는 직관적인데, reduce의 경우에는 잘 와닿지 않을 수 있습니다. 이를 위해서 간단한 예제를 들고 와 보면,
# 구문
Value: id
Products: Value | Products '*' Value
Sums: Products | Sums '+' Products
Assign: id '=' Sums
# input
id = B + C*2
# 파싱
0 empty
1 id
2 id =
3 id = id
4 id = Value (Reduce by Products ← Value)
5 id = Products (Reduce by Sums ← Products, 3중으로 reduction 발생)
6 id = Sums (다음 symbol이 '+' 이므로, 여기서는 Shift가 발생합니다!)
7 id = Sums +
8 id = Sums + id (Reduce)
9 id = Sums + Value
10 id = Sums + Products ('*' 으로 shift 발생)
11 id = Sums + Products *
12 id = Sums + Products * int (Reduce)
13 id = Sums + Products * Value (Reduce가 발생하면서 Products ← Products * Value)
14 id = Sums + Products (Reduce by Sums ← Sums + Products)
15 id = Sums (Reduce by Assign ← id = Sums)
16 Assign가 되어서, 완벽하게 Bottom-up 파서의 모습을 보여주게 됩니다.
Dangling else problem
하지만 LALR 방식의 파서가 무안단물은 아닙니다. 문법간 충돌이 일어나는 경우도 있는데, 대표적인 경우가 바로 이 경우로서 파서의 Ambiguity를 설명할 때 나오는 대표적인 문제 중 하나입니다. Wikipedia 참고
if a then if b then s else s2
=> if a then (if b then s) else s2
=> if a then (if b then s else s2)s 근처에서 reduce를 하냐, shift를 하냐에 따라 전혀 다른 방식으로 식이 해석됩니다. (S/R conflict)
보통 이러한 경우 아예 문법을 바꿔서 괄호를 포함하도록 만들거나
(CS가 싫어합니다)
, shift를 reduce 우선으로 만들거나 하여 문제를 해결하게 됩니다.
비슷한 케이스로 사칙 연산 (덧셈 / 뺄셈 같이 나오는 경우)가 있습니다. 1+2*3 같은 경우, ‘+’와 ‘’을 같은 expression 레벨에 놓으면 ambiguity가 발생합니다. *다만 곱셈과 덧셈 expression을 다른 레벨로 놓으면 이런 문제가 발생하지는 않긴 하는데 일종의 편의상(?) 그냥 precedence 넣어서 처리하게 되던…
Conflict
위에서 살펴본 것처럼 parser conflict이 존재할 수 있고, 이러한 Conflict의 종류에는 2가지가 있습니다.
- S/R conflict: Shift를 할 지, Reduce를 할 지 알 수 없음
- R/R conflict: 어느 Reduce를 할 지 알 수 없음
S/S conflict도 있지 않나요? 라고 물을 수 있는데, 잘 생각해 보면 이 경우는 같은 state로 퉁치니까 “conflict”이 애당초 아니죠?
S/R 방식은 위에서의 “else 문제”처럼 보통 precedence 주어서 해결하곤 합니다. 그러면 R/R은 대체 뭐죠? 바로 어떠한 방식으로 reduce 되어야 할 지 모호한 경우에 이러한 문제가 발생하게 됩니다.
예를 들어,
funcA <- 'func' '(' 'A' ')' | 'func' '(' num ')'
funcB <- 'func' '(' 'B' ')' | 'func' '(' num ')'
expr <- funcA | funcB와 같은 식이 있다고 가정을 하면, func(123) 과 같은 경우 funcA로 Reduce 할지, funcB로 Reduce 할 지 알 수 없게 됩니다.
R/R 문제의 경우 S/R과는 다르게 precedence를 지원하지 않기 때문에 (적어도 제가 봤던 generator들은 그랬습니다. 아무래도 stack pop을 하다 보니 이전 상태로 되돌아가는 백트래킹이 어려워 그런가 봄) 훨씬 문제가 심각합니다. 따라서 해당 오류가 발생했다면 유의깊게 문법을 재검토할 필요가 있습니다.
CFG(Context-free grammar) 파서
사실 이건 별 게 아니고 결국 파서 언어의 정의입니다. LALR도 CFG중 하나에 속합니다.
문맥 자유 문법이라고 불리는데, 이것 또한 Wikipedia의 설명을 보면,
A formal grammar is "context free" if its production rules can be applied regardless of the context of a nonterminal. No matter which symbols surround it, the single nonterminal on the left hand side can always be replaced by the right hand side. This is what distinguishes it from a context-sensitive grammar.즉 기존의 non-terminal 심볼들(맥락=context)을 신경쓸 필요 없이, 단 하나의 non-terminal ⇒ terminal 방식으로 문법 정의가 되어있는 경우에 대해서 context-free 파서라고 합니다. PL하면 한번쯤 접해봤을 이론인데…
아무튼, 언어의 정의 G 는 아래와 같이 쓸 수 있습니다.

뭔가 많은데 그냥 파서를 구성하는 요소들인 입력 (터미널)심볼, 시작(심볼), 규칙들, 규칙명 정도가 됩니다.
그리고 주어진 언어(입력) L 이 이 G 가 만들어 낼 수 있는 조합에 속한다면, 이는 정상적인 입력이라고 할 수 있겠습니다 (CFG에 속한다라고 이야기 함)
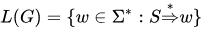
간단한 예시로
S -> aSa
S -> bSb
S -> (terminal)
가 있을 때, aabbaa는 파싱이 가능한 언어인가? (Y)
해설:
S -> aSa -> aaSaa -> aabSbaa -> aabbaa
이기 때문입니다.보시면 언어의 정의 자체가 단 하나의 non-terminal (S) 에서 non-terminal | terminal 로 만들어지는 구조입니다.
- 그렇다고 unambiguous 하지는 않습니다. 물론 Algebra의 ambiguous한 식 (대충 덧셈 곱셈 섞은 식…)에서는 얄짤 없으나 여기서는 precedence를 사용하는 게 국룰이기 때문에…
- LALR도 CFG에 속합니다; 정확히는 Deterministic context-free language입니다. 즉 LALR은 Unambiguous한 CFG라는 것인데, 현실적으로 그러한 경우는 거의 없다고 봐야… 그래서 GLR을 쓰게 되는 것이죠.
그래서 이걸 어디에 어떻게 써먹냐? 의외로 Albegra 식에서도 잘 써먹을 수 있습니다.

이처럼 non-terminal S를 이용해서 충분히 CFG가 만들어지는것이 보입니다.
고전적인 CFG 파서 중 하나가 Earley parser라고 하는데 그냥 한번 훑어만 보면 될 듯 싶습니다, 어차피 GLR이 저거 다 계산해서 테이블 만들어 주는데 뭐
PEG(Parsing expression grammar) 파서
Wikipedia의 설명을 보면… 결국 CFG와 같은 사상을 가지고 있습니다. 다만 PEG의 경우에는 unambiguous 한 output(tree)가 생성된다는 것을 보장한다고 합니다 (priortization 때문에). 그냥 먼저 정의된 Rule를 무조건 먼저 매치시키는 방식이라고 생각하면 됩니다.
대표적인 구현은 “packrat parser” 방식이라고 하는데, 방식은 아주 간단합니다. 주어진 state에서 모든 가능한 다른 함수로의 shift/reduce를 수행하고, memoization 하는 것인데… 메모리 소모량이 끔찍할 것이 자명해서 그렇게 구미가 당기는 방식은 아닙니다 😥
그리고 packrat parser 자체에서 해석할 수 있는 expression의 한계 또한 있다고 알려 져있습니다. 자세한 건 wikipedia 참고.
Flex/Bison
여기서 설명할 Flex/Bison는 각각 lexer/parser에 해당이 됩니다. 그 중에서도 Flex는 Yacc 문법을 따르는 parser generator입니다. Yacc 문법 자체는 별 것 없습니다… LALR 파서젠들에게서 통상적으로 쓰이는 형태라고 보시면 됩니다.
대표적인 LALR 및 GLR(CFG) 형태의 파서이고, 이에 대한 세부 내용은 위에서 다 썼으니 간단하게 세부 내용만 짚고 넘어가겠습니다 ㅎㅎ.
검증
Bison 파서의 경우, yacc 파일을 주면 자동으로 state table을 생성해 줍니다. 그리고 state table을 생성하는 동안의 정보를 읽기 쉬운(?) output 파일로 만들어 주는 기능이 있습니다.
bison parser.y -v --header=parser.h --report-file="parser.output.txt" --graph="parser.output.dot"이처럼 단순 txt 파일 뿐만 아니라 .dot 형태의 Graph 형태로도 뽑아서 확인할 수 있어서 굉장히 도움이 됩니다. 또 State table을 만들다 보면 자연히 S/R, R/R conflict를 검증하게 되므로, 이에 대한 정보도 여기에서 확인할 수 있다는 것 또한 이점입니다.
한 가지 염두에 두어야 할 것은 output은 내부적으로 생성된 state table을 기준으로 만들어지게 됩니다. 즉 본래의 rule을 보여주는 것이 아니라 state table을 직접 보고서 어떤 rule들끼리 conflict가 발생했는지 직접 찾아나가야 합니다. 이게 약간 골치아픈 점. (이 부분을 보강해서 source line과 연동해주는 툴을 만들면 참 좋겠다~고 생각은 했으나 실천하지는 아니하였습니다 😅)
트릭: Custom Lexer, Parser 설계
파싱해야 하는 문법 자체가 모호하지 않고 완벽하다면 얼마나 좋겠습니다만, 현실에서 파서 작업을 하다보면 그게 녹록치 않은 경우가 참 많습니다. identifier을 파싱해야 하는 언어들이 많이들 그러하고, 그리고 그 대표적인 케이스 중 하나가 SQL 문법입니다.
일례로 아래와 같은 문법이 있다고 가정해 보겠습니다. (Note: 매우 간략화 한 예시입니다)
pivot_expr: 'PIVOT' '(' column_names ')'
column_names : column_names column | column
column: identifier | pivot_expr
tables: tables table_expr | table_expr
table_expr: identifier | identifier '(' column_names ')'
identifier: ... | PIVOT | ...이 경우 아래와 같은 문법들이 모두 허용됩니다.
SELECT a from pivot; // pivot라는 테이블에서 A Column을 가져옴
SELECT pivot(a) from tbl; // TBL이라는 테이블에서 A 컬럼을 가져오고 pivot 수행이론상으로는 충분히 모호하지 않다고 생각할 수 있는 문법이지만, LALR은 여기에서 R/R 충돌을 탐지합니다. pivot(a) 가 column expression인지, Table expression인지 알 수 없는 노릇이기 때문이죠.
하지만 우리는 SELECT 와 FROM 절 사이의 모든 expression들이 identifier (혹은 Function name)들에 해당된다는 것을 알고 있습니다. 따라서, Flex의 output과 Bison input 사이에 추가 lexer 후처리기를 넣어서, 해당 token을 column identifier로 해석하도록 강제하여 이를 Parser에서 받아주도록 하면 쉽게 문법을 짤 수 있습니다.
for _, token in range tokens {
if between SELECT and FROM {
token.type = COLUMN_ID
}
}사실 이건 SQL 특성에 따라, SELECT와 FROM 사이의 토큰인지를 확인하기 위한 context가 있어야 하는 부분이기 때문에 해당 파서의 기본 설계 사상인 CFG(Context-free grammar)에서는 구현할 수 없는 부분이 됩니다.
하지만 뭐… 가끔 규율은 어쩔수 없이 어겨야 하는 부분이 있기 때문에
적당히 트릭을 사용하면 CFG 문법으로도 이렇게 모호한 구문을 해석하기에 충분하도록 만들 수 있는 게 핵심.
이외에도 lexer 자체에서 state(context)를 주어서 토큰을 조율하는 방법도 있습니다. 어느 쪽이든 상황에 맞는 형태로 가공해서 쓰면 되는 부분이라고 생각합니다 ㅎㅎ.
트릭2: 시작 상태 전달하기
가끔은 파서에 특수한 상태를 주고 싶을때가 있습니다. 예를 들면 파싱시 어떤 플래그를 켜면 특정 구문만 읽게 하고 싶다던가... 하지만 Bison은 Context-free 잖아요? 난감합니다.
하지만 이 또한 lexer에 약간의 트릭을 가하면 쉽게 구현할 수 있습니다. 이를테면, 특수한 구문을 읽게 만들고 싶을 경우에는 파서를 호출하기 직전에 lexer의 결과 맨 앞에 MODE_SPECIAL 같은 토큰을 넣고, parser에서 이를 읽으면 특수한 구문을 해석하는 Rule로 shift 하도록 구현하면 되는 일이죠. 좋은 예가 Stackoverflow에 있습니다.
몇 달간 미루고 미루다가 (깊이는 많이 부족하지만) 드디어 파서 관련 내용을 까먹기 전에 정리해 둡니다. 속시원하네 ㅎㅎ.
'개발 > Algorithm' 카테고리의 다른 글
| Audio Data의 Pitch를 변경해보자 (0) | 2022.08.31 |
|---|---|
| 자주 나오는 대회용 알고리즘 정리 (0) | 2022.08.30 |
| 몇 가지 Greedy (0) | 2022.07.29 |
| 최소 공통 조상 구하기 (LCA) (0) | 2022.07.28 |
| K개의 구간합 구하기 (0) | 2022.07.28 |